近日,斯坦福大学研究人员发布的 Octopus v2模型引起了开发者社区的极大关注,其20亿参数的模型一夜下载量超过2k。
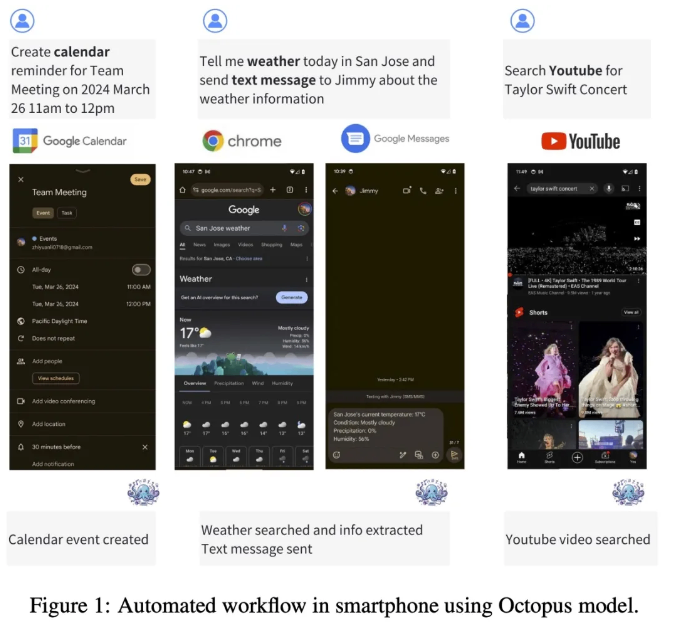
这一模型可以在智能手机、汽车、个人电脑等端侧设备上运行,并在准确性和延迟方面表现超越了 GPT-4,同时将上下文长度减少了95%。Octopus v2还比 Llama7B + RAG 方案快了整整36倍,展示了端侧 AI 智能体的崛起。
Octopus v2的设计独特之处在于其函数性 token 策略,使其能够实现与 GPT-4相当的性能水平,同时大幅提高推理速度,超越基于 RAG 的方法,对边缘计算设备特别有利。模型在生成单独的、嵌套的和并行的函数调用时表现优异。为了训练该模型,研究团队采用了高质量数据集,并使用 Google Gemma-2B 作为预训练模型框架。训练过程中采用了完整模型训练和 LoRA 模型训练两种方法,展现了 Octopus v2在推理速度和准确性方面的优异表现。
在基准测试中,Octopus v2表现出卓越的推理速度,比 Llama7B + RAG 解决方案快36倍,在准确率上也超越了其他方案。这种效率和性能的提升归功于 Octopus v2的函数性 token 设计,使其成为端侧设备上极具竞争力的 AI 智能体。设备端 AI 智能体时代即将到来,Octopus v2的发布为这一趋势注入了新的活力。
论文:https://arxiv.org/abs/2404.01744
产品入口:https://huggingface.co/NexaAIDev/Octopus-v2
本文来源于#站长之家,由@tom 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/918.html





















