牛津大学工程科学系的视觉几何组开发了一款名为 Magi 的Ai模型,可以自动将漫画页转录成文字并生成剧本。该模型通过识别漫画页面上的面板、文字块和角色,实现了全自动的剧本生成功能。其主要功能包括面板检测,识别漫画页面上的各个面板,以及文本块检测,识别面板中的文本块,通常包含对话或叙述性文本。此外,模型还能够检测页面上的角色形象,并根据其身份进行聚类,以区分不同的角色。
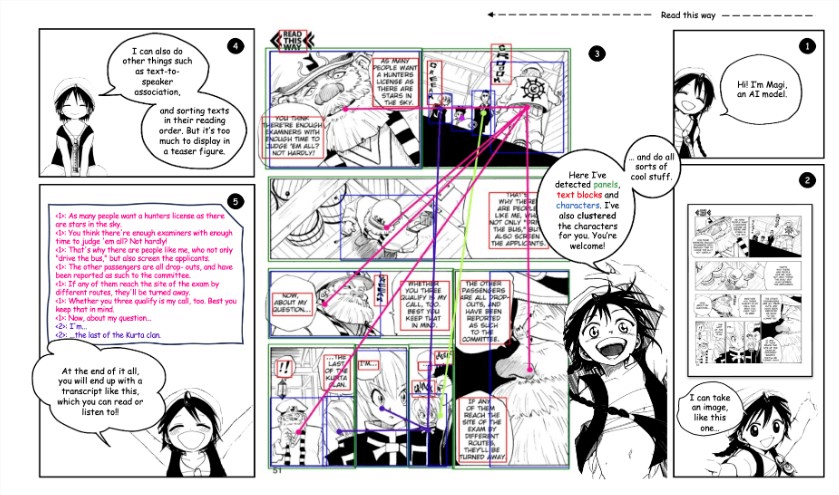
Magi 模型还可以将文本与说话者进行关联,确定哪些文本是由页面上的哪个角色说出的,保证剧本的准确性。同时,模型还会按照漫画的阅读顺序对文本块进行排序,确保剧本的叙述逻辑与原漫画一致,让读者通过阅读文本完整地体验漫画故事。
除了 Magi 模型本身,项目还包含一个名为 Mangadex-1.5M 的数据集,其中包含约150万漫画页面,涵盖多种流派和艺术风格。这个数据集的设计旨在为 Magi 模型的训练提供支持,解决漫画页面的自动理解和剧本生成问题,包括面板检测、文本块和角色检测、角色身份聚类以及文本与说话者之间的关联。
通过这一项目,研究人员希望推动漫画领域的自动化处理和理解技术的发展。
论文:https://arxiv.org/abs/2401.10224
项目入口:https://github.com/ragavsachdeva/magi
本文来源于#站长之家,由@tom 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/757.html
THE END


的人体姿态估计模型")

开源的超长文本生成模型")
















