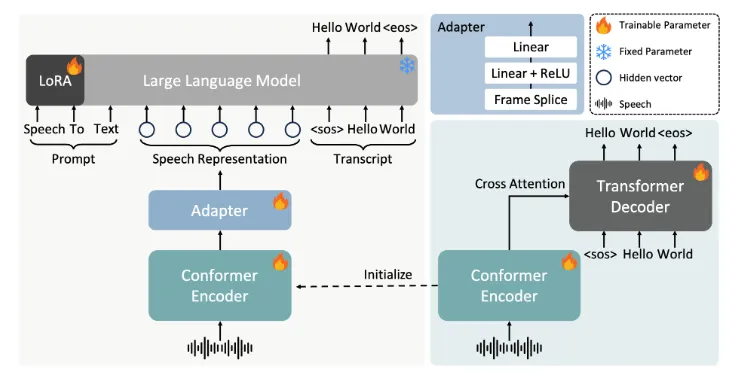
一、FireRedASR概述
FireRedASR是由小红书FireRed团队开发并开源的一款基于大模型的自动语音识别(ASR)系统。这款语音识别系统不仅在中文识别领域取得了显著突破,还在多语言支持、高效推理等方面展现出强大的性能。FireRedASR的发布标志着语音识别技术进入了一个新的发展阶段,为智能语音交互和多媒体内容理解领域带来了全新的可能。
二、FireRedASR功能特色
1.卓越的中文识别能力
FireRedASR在中文识别领域取得了新的SOTA(State of the Art)水平,特别是在普通话识别方面表现尤为突出。通过先进的深度学习技术和大规模的训练数据,FireRedASR能够高效地将普通话语音转化为文字,且识别准确率极高。无论是在安静环境下还是在嘈杂背景中,FireRedASR都能保持稳定的识别性能。
2.多语言支持
除了普通话识别外,FireRedASR还支持中文方言和英语的识别。这意味着用户可以在不同语言环境下使用FireRedASR进行语音交互,无需切换不同的识别系统。这一特性极大地拓宽了FireRedASR的应用范围,使其能够满足更多用户的多样化需求。
3.高效的推理能力
FireRedASR在追求高准确率的同时,也注重推理效率的提升。通过优化模型结构和算法设计,FireRedASR能够在保持高准确率的同时实现快速的推理速度。这使得FireRedASR能够在各种实时应用场景中发挥出色表现,如语音助手、实时字幕等。
4.灵活的配置和扩展性
FireRedASR提供了灵活的配置选项和扩展性支持。用户可以根据自己的需求选择不同的模型参数和配置选项,以适应不同应用场景的需求。同时,FireRedASR还支持自定义词库和语法规则等功能,以满足用户在特定领域或场景下的定制化需求。
5.开源共享
FireRedASR是一个开源项目,其模型和推理代码均已公开。这使得更多的开发者和研究者能够参与到FireRedASR的改进和扩展中来,共同推动语音识别技术的发展。同时,开源共享的特性也使得FireRedASR能够更广泛地应用于各种领域和场景中。
三、FireRedASR技术细节
1.核心架构
FireRedASR系列模型包含两种核心结构:FireRedASR-LLM和FireRedASR-AED。
FireRedASR-LLM:采用Encoder-Adapter-LLM框架,结合了大型语言模型(LLM)的能力。这种结构使得FireRedASR-LLM能够充分利用LLM在文本处理方面的优势,从而实现极致的语音识别精度。
FireRedASR-AED:采用基于注意力的编码器-解码器(AED)架构。这种结构通过引入注意力机制来捕捉输入语音和输出文本之间的长距离依赖关系,从而提高了语音识别的准确率。同时,AED架构还具有良好的平衡性能,能够在保持高准确率的同时实现高效的推理速度。
2.训练和优化
FireRedASR的训练和优化过程涉及多个方面:
大规模数据集:FireRedASR的训练数据集包含大量高质量的语音样本和对应的文本标签。这些数据涵盖了不同口音、语速和噪声环境下的语音信号,为模型的泛化能力提供了有力保障。
先进的深度学习技术:FireRedASR采用了多种先进的深度学习技术,如卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等。这些技术能够捕捉输入语音中的复杂特征,并将其转化为易于处理的表示形式。
优化算法:在训练过程中,FireRedASR采用了多种优化算法来加速模型的收敛过程并提高识别准确率。这些算法包括随机梯度下降(SGD)、Adam等。
3.推理和部署
FireRedASR的推理和部署过程相对简单:
模型加载:用户可以通过API接口将训练好的FireRedASR模型加载到本地或云端服务器中。加载过程通常包括模型参数的读取和内存分配等操作。
输入处理:在推理阶段,用户需要将待识别的语音信号输入到FireRedASR模型中。输入处理过程包括语音信号的预处理(如去噪、采样率转换等)和特征提取等操作。
模型推理:FireRedASR模型会对输入语音信号进行推理计算,并输出对应的文本结果。推理过程通常包括前向传播和输出解码等操作。
结果输出:最终输出的文本结果可以通过API接口返回给用户或集成到其他应用程序中。
四、FireRedASR应用场景
1.语音助手
FireRedASR可以应用于各种语音助手场景中,如智能手机、智能家居设备等。通过语音识别技术,用户可以方便地与设备进行交互,完成各种任务操作。
2.实时字幕
在视频直播、在线教育等场景中,FireRedASR可以实现实时字幕功能。用户可以将语音信号实时传输到FireRedASR模型中进行处理,并获取实时的文字识别结果。这对于听力障碍者或者需要多语言支持的用户来说非常有用。
3.智能客服
FireRedASR可以应用于智能客服系统中,实现自动语音识别和文本转换功能。这样可以大大提高客服系统的工作效率和服务质量,降低人力成本。
4.语音输入
在移动应用、网页端等场景下,FireRedASR可以实现语音输入功能。用户可以通过语音输入来快速完成文字输入操作,提高输入效率。
5.歌词识别
FireRedASR还可以应用于歌词识别场景中。通过识别歌曲中的语音信号,FireRedASR可以自动提取出歌词内容,为音乐爱好者提供便捷的歌词查询和同步显示功能。
五、相关链接
GitHub项目地址:https://github.com/FireRedTeam/FireRedASR
技术报告和文档说明:http://arxiv.org/abs/2501.14350
官方博客和社区支持:https://fireredteam.github.io/demos/firered_asr/
六、总结
FireRedASR作为一款基于大模型的自动语音识别系统,在中文识别领域取得了显著的突破,并在多语言支持、高效推理等方面展现出强大的性能。其卓越的功能特色和先进的技术细节使得FireRedASR在各种应用场景中都具有广泛的应用前景。通过开源共享的方式,FireRedASR不仅促进了语音识别技术的发展和普及,也为更多开发者和研究者提供了宝贵的资源和支持。相信在未来,FireRedASR将继续发挥其优势作用,为用户带来更加便捷、高效的语音交互体验。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3127.html

的语音识别模型")















