VideoWorld是什么?
VideoWorld是由北京交通大学、中国科学技术大学和字节跳动联合开发的一款自回归视频生成模型。该模型旨在探索深度生成模型是否能够通过未标注的视频数据学习复杂知识,包括规则、推理和规划能力。与传统的视频生成技术不同,VideoWorld摒弃了依赖语言模型或人工标注数据的传统方式,而是通过纯视觉信号的学习,实现了对世界的认知和理解。
功能特色
1. 无需依赖语言模型或人工标注数据
VideoWorld的最大亮点之一是其无需依赖语言模型或人工标注数据。传统的视频生成技术大多需要借助语言模型来理解视频内容,或者依赖大量的人工标注数据来训练模型。然而,这种方式不仅效率低下,而且成本高昂。而VideoWorld则通过纯视觉信号的学习,实现了对视频内容的理解和生成,极大地降低了数据准备的成本和时间。
2. 高效的视频生成与任务推理
VideoWorld采用先进的自回归视频生成技术,结合矢量量化-变分自编码器(VQ-VAE)和自回归Transformer架构,实现了高效的视频生成与任务推理。通过生成高质量的视频帧,VideoWorld能够推断出任务相关的操作,并在各种复杂任务中表现出色。这种能力使得VideoWorld在围棋、机器人控制、自动驾驶等领域具有广泛的应用前景。
3. 强大的跨环境泛化能力
VideoWorld还具备强大的跨环境泛化能力。它能够在不同的任务和环境中迁移所学的知识,并在新的场景中表现出色。这种能力使得VideoWorld在应对新任务和新环境时能够迅速适应,提高模型的实用性和可靠性。
4. 紧凑的视觉信息表示
VideoWorld引入潜在动态模型(LDM),将冗长的视觉信息压缩为紧凑的潜在代码,减少了信息冗余,提高了学习效率。这种紧凑的视觉信息表示方式使得VideoWorld在处理大量视频数据时能够保持高效和准确。
技术细节
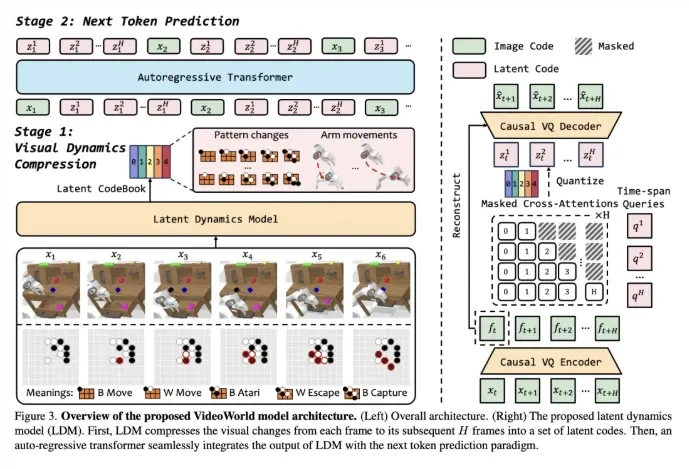
1. VQ-VAE与自回归Transformer架构
VideoWorld的核心技术之一是VQ-VAE与自回归Transformer架构的结合。VQ-VAE用于将视频帧编码为离散的token序列,而自回归Transformer则根据前面的帧预测下一帧,从而生成连贯的视频序列。这种结合使得VideoWorld能够生成高质量的视频帧,并通过生成的视频帧推断出任务相关的操作。
2. 潜在动态模型(LDM)
LDM是VideoWorld的另一个关键技术。它将多步视觉变化压缩为紧凑的潜在代码,提高了知识学习的效率和效果。LDM能够捕捉视频中的短期和长期动态,支持复杂的推理和规划任务。通过LDM的引入,VideoWorld在处理大量视频数据时能够保持高效和准确。
3. 逆动态模型(IDM)
在生成视频帧的基础上,VideoWorld还通过逆动态模型(IDM)将生成的视频帧映射为具体的任务操作。IDM能够根据当前帧和预测帧生成相应的动作指令,从而实现视频生成与任务操作的映射。这种能力使得VideoWorld在机器人控制、自动驾驶等领域具有广泛的应用前景。
应用场景
1. 围棋对战
VideoWorld在围棋对战中表现出色。它能够进行长期规划,选择最佳落子位置并击败高水平的对手。通过生成高质量的视频帧和进行复杂的推理计算,VideoWorld在围棋对战中展现出了强大的实力。
2. 机器人控制
在机器人控制领域,VideoWorld也展现出了广泛的应用前景。它能够规划复杂的操作序列,完成多种机器人控制任务。通过生成的视频帧和潜在代码,VideoWorld能够理解复杂的视觉信息,并支持任务驱动的推理和决策。这使得VideoWorld在机器人控制、自动化生产等领域具有巨大的应用潜力。
3. 自动驾驶
自动驾驶是VideoWorld的另一个重要应用场景。通过生成高质量的视频帧和进行复杂的推理计算,VideoWorld能够理解复杂的交通环境并做出正确的驾驶决策。这种能力使得VideoWorld在自动驾驶领域具有广泛的应用前景。
4. 智能监控
智能监控是VideoWorld的另一个重要应用场景。通过生成高质量的视频帧和进行复杂的推理计算,VideoWorld能够理解监控视频中的复杂场景并识别出异常事件。这种能力使得VideoWorld在智能监控、安全防范等领域具有广泛的应用前景。
相关链接
项目主页:VideoWorld项目主页
GitHub仓库:VideoWorld GitHub仓库
技术论文:VideoWorld技术论文
总结
VideoWorld作为一款创新的自回归视频生成模型,在视频生成领域展现出了巨大的潜力。它无需依赖语言模型或人工标注数据,通过纯视觉信号的学习实现了对世界的认知和理解。同时,VideoWorld还具备高效的视频生成与任务推理能力、强大的跨环境泛化能力以及紧凑的视觉信息表示方式。这些特点使得VideoWorld在围棋、机器人控制、自动驾驶等领域具有广泛的应用前景。
随着AI技术的不断发展,视频生成技术也将迎来更多的创新和突破。我们相信,VideoWorld作为这一领域的佼佼者,将继续发挥其独特优势,为视频生成技术的发展贡献更多力量。我们期待在未来的发展中,VideoWorld能够带来更多令人惊叹的成果和突破。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3110.html





















