随着数字技术的飞速发展,三维数字人生成技术在数字娱乐、虚拟形象、数字孪生以及元宇宙等领域的应用前景日益广阔。南洋理工大学S-Lab团队提出了一种新型的三维数字人生成范式——结构化隐空间扩散模型(Structured Latent Diffusion Model,简称StructLDM)。StructLDM通过结构化潜在空间、3D感知解码器和潜在扩散模型,实现了高质量、多样化的三维数字人生成与编辑,为数字孪生、元宇宙等领域的发展注入了新的活力。

一、StructLDM是什么
StructLDM是一种从2D图像集合中生成3D人体的新型范式。它利用先进的深度学习技术和计算机视觉算法,从图像和视频中学习人体的高维表征,并通过结构化的自动解码器和隐空间扩散模型生成高质量、多样化的三维数字人。相比于传统的3D生成对抗网络(GAN)方法,StructLDM具有更高的生成质量、更好的视角一致性和更强的可控性生成与编辑功能。
二、功能特色
1. 高质量、多样化生成
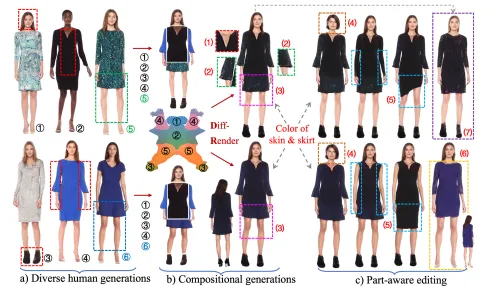
StructLDM能够生成高质量、多样化的三维数字人。这些数字人具有逼真的外观和精细的细节,包括不同的肤色、发型、服饰等。通过调整生成参数和模型结构,StructLDM可以生成具有不同风格和特征的三维数字人,满足用户的个性化需求。
2. 视角一致性
StructLDM生成的三维数字人在不同视角下具有一致性。这得益于其结构化潜在空间的设计,该空间能够捕捉到人体的精细结构和语义信息,并在不同视角下保持一致性。这使得StructLDM生成的三维数字人在虚拟场景中具有更强的真实感和沉浸感。
3. 可控性生成与编辑
StructLDM支持不同级别的可控性生成与编辑功能。用户可以通过调整生成参数和编辑工具来控制数字人的姿态、视角、体型等属性。此外,StructLDM还支持局部服装编辑、三维虚拟试衣等高级编辑任务,使得用户能够根据自己的需求对生成的三维数字人进行精细的定制和调整。
4. 高效的生成与编辑流程
StructLDM采用了结构化的自动解码器和隐空间扩散模型,实现了高效的生成与编辑流程。自动解码器能够将潜在空间中的高维表征解码为三维数字人,而隐空间扩散模型则通过学习潜在空间的分布来生成新的数字人。这种设计使得StructLDM能够在保证生成质量的同时,提高生成和编辑的效率。
三、技术细节
1. 结构化潜在空间
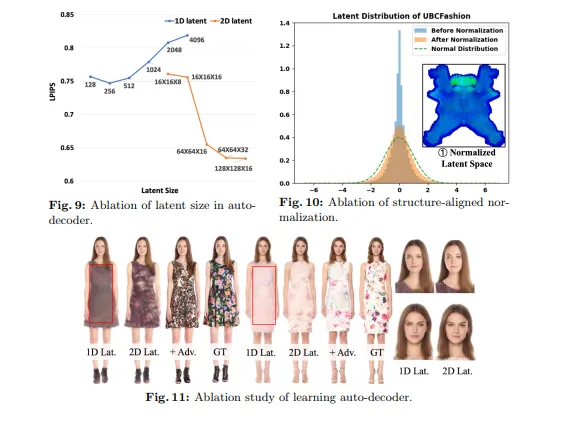
StructLDM定义了一个基于统计人体模板的密集表面流形上的语义结构化潜在空间。这种结构化表示能够更好地捕捉人体的精细细节和语义信息,为后续的数字人生成和编辑提供了坚实的基础。结构化潜在空间通过分解全局潜在空间为几个语义身体部分,并使用一组条件结构化局部神经辐射场(NeRF)锚定到身体模板上,从而嵌入从二维训练数据中学习到的属性。
2. 结构化3D感知解码器
StructLDM采用了一种结构化3D感知解码器,该解码器能够将潜在空间中的高维表征解码为三维数字人。解码器通过分解全局潜在空间为几个语义身体部分,并使用一组条件结构化局部NeRF锚定到身体模板上,从而实现对不同姿态和服装风格下具有一致视角的三维数字人的解码。此外,为了解决姿态估计误差问题,自动解码器训练过程中引入了对抗式学习。
3. 结构化潜在扩散模型
StructLDM使用了一个结构化潜在扩散模型来生成人体外观。该模型通过学习第一阶段得到的UV latent空间,以此学习人体三维先验。在推理阶段,StructLDM可以随机生成三维数字人:随机采样噪声并去噪得到UV latent,该latent可以被自动解码器渲染为人体图像。由于潜在空间是结构化的且语义上对齐的,该模型通过使用结构对齐的归一化来进一步调整扩散过程,以更好地捕捉数据的分布。
四、应用场景
StructLDM在多个领域具有广泛的应用前景,包括但不限于数字娱乐、虚拟形象、数字孪生以及元宇宙等。
1. 数字娱乐
在数字娱乐领域,StructLDM可以生成高质量的三维数字人角色,为游戏、动画等提供丰富的素材。游戏开发商可以利用StructLDM生成多样化的角色模型,满足玩家的个性化需求。同时,StructLDM还支持可控性生成和编辑功能,使得游戏角色具有更高的可定制性和互动性。
2. 虚拟形象
在虚拟形象领域,StructLDM可以生成逼真的虚拟人物,用于社交、直播等场景。用户可以根据自己的喜好定制个性化的三维虚拟形象,并通过StructLDM提供的编辑工具进行调整和优化。这种虚拟形象不仅具有高度的真实感,还具有丰富的表情和动作变化,能够增强用户的沉浸感和互动性。
3. 数字孪生
在数字孪生领域,StructLDM可以生成与真实人物高度相似的三维数字人模型,用于模拟、训练等场景。例如,在医疗领域,医生可以利用StructLDM生成患者的三维数字人模型,进行手术模拟和训练,提高手术成功率和安全性。此外,StructLDM还可以用于工业制造、航空航天等领域的数字孪生建模和仿真分析。
4. 元宇宙
在元宇宙领域,StructLDM更是可以发挥重要作用。元宇宙是一个虚拟的现实世界,其中包含了大量的三维数字人和虚拟场景。StructLDM可以生成高质量的三维数字人角色和场景元素,为元宇宙的构建和丰富提供有力的支持。同时,StructLDM还支持可控性生成和编辑功能,使得用户在元宇宙中具有更高的自主性和创造性。
五、相关官方链接
StructLDM的相关研究论文和项目页面可以在以下链接中找到:
项目页面:https://taohuumd.github.io/projects/StructLDM/
论文链接:StructLDM: Structured Latent Diffusion for 3D Human Generation
Github地址:https://github.com/TaoHuUMD/StructLDM
六、总结
StructLDM作为一种新型的三维数字人生成范式,凭借其高质量、多样化生成、视角一致性、可控性生成与编辑以及高效的生成与编辑流程等特点,在数字娱乐、虚拟形象、数字孪生以及元宇宙等领域具有广泛的应用前景。南洋理工大学S-Lab团队提出的StructLDM不仅为三维数字人技术的发展开辟了新的道路,也为相关领域的创新和发展提供了新的思路和方法。随着深度学习技术的不断进步和计算机视觉领域的持续发展,相信StructLDM将在未来实现更加广泛的应用和更加深入的创新。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3008.html




的人体姿态估计模型")
















