在计算机视觉领域,人体姿态估计是一项具有挑战性的任务,它涉及到从图像或视频中检测和跟踪人体的各个关键点。近年来,随着深度学习技术的发展,特别是卷积神经网络(CNN)的应用,人体姿态估计取得了显著的进展。然而,传统的 CNN 模型在处理复杂场景时仍存在一些局限性。为了克服这些局限性,研究人员开始探索基于视觉变换器(Vision Transformer, ViT)的方法。ViTPose 是一种基于简单视觉变换器的基线模型,用于人体姿态估计。尽管在设计中没有考虑特定领域的知识,但纯视觉变换器在视觉识别任务中表现出色。
ViTPose 是什么
定义与背景
ViTPose 是一种基于视觉变换器(ViT)的人体姿态估计模型。视觉变换器最初由 Google Research 提出,用于图像分类任务,其核心思想是将图像分割成多个小块(patch),然后通过自注意力机制(self-attention mechanism)来捕捉这些小块之间的关系。与传统的卷积神经网络相比,视觉变换器在处理长距离依赖关系方面具有更强的能力,这使得它在人体姿态估计等任务中表现出色。
设计理念
ViTPose 的设计理念是利用视觉变换器的强大力量,结合轻量级解码器,实现高效且准确的人体姿态估计。该模型结构简单,但性能强大,能够在多种场景下提供高质量的姿势估计结果。
功能特色
1. 简单的模型结构
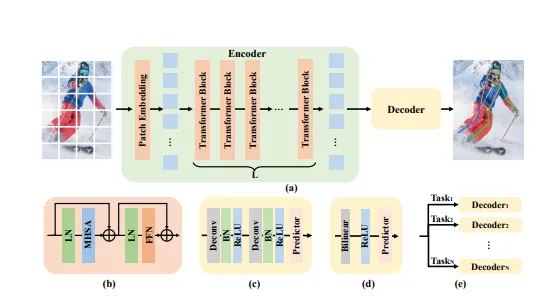
ViTPose 使用非层次化的视觉变换器作为骨干网络,提取图像特征。这种简单的结构不仅易于实现,而且在训练和推理过程中具有较高的效率。与复杂的多阶段模型相比,ViTPose 的结构更加简洁明了,便于理解和优化。
2. 可扩展的模型大小
ViTPose 支持从 100M 到 1B 的模型参数规模,这使得用户可以根据实际需求选择合适的模型大小。通过利用变换器的可扩展模型容量和高并行性,ViTPose 能够在不同的硬件平台上实现最佳性能。这种灵活性使得 ViTPose 在资源受限的设备上也能表现出色。
3. 灵活的训练范式
ViTPose 支持多种注意力机制、输入分辨率、预训练和微调策略,以及处理多个姿态任务。这种灵活的训练范式使得 ViTPose 能够适应不同的数据集和应用场景,从而提高模型的泛化能力。
4. 知识可转移
ViTPose 通过引入简单的知识令牌(knowledge token),可以轻松地将大型 ViTPose 模型的知识转移到小型模型中。这种知识转移机制不仅提高了小型模型的性能,还减少了训练时间和计算资源的消耗。
5. 优秀的实验结果
ViTPose 在 MS COCO Keypoint Detection 基准测试中表现出色,基本的 ViTPose 模型已经优于其他代表性方法,而最大规模的模型则达到了新的最先进水平。这些实验结果证明了 ViTPose 在人体姿态估计任务中的优越性能。

技术细节
1. 模型架构
骨干网络:ViTPose 的骨干网络采用非层次化的视觉变换器(ViT)。具体来说,输入图像首先被分割成多个小块(patch),每个小块被展平并投影到一个固定维度的向量空间中。这些向量随后被送入多层变换器编码器,通过自注意力机制和前馈神经网络进行特征提取。
解码器:ViTPose 的解码器部分相对简单,主要由几个卷积层组成。这些卷积层负责将变换器提取的特征图转换为最终的关节点热图。通过这种方式,ViTPose 能够高效地生成高质量的姿势估计结果。
2. 训练过程
数据预处理:在训练过程中,输入图像需要经过一系列预处理步骤。首先,图像被缩放到统一的分辨率,然后被分割成多个小块(patch)。每个小块被展平并投影到一个固定维度的向量空间中,形成输入序列。
损失函数:ViTPose 使用均方误差(Mean Squared Error, MSE)作为损失函数,用于衡量预测的关节点热图与真实标签之间的差异。此外,还可以使用其他损失函数(如交叉熵损失)来进一步优化模型性能。
预训练与微调:ViTPose 支持多种预训练和微调策略。常见的预训练策略包括在大规模图像分类数据集(如 ImageNet)上进行预训练,然后再在人体姿态估计数据集上进行微调。这种预训练和微调策略有助于提高模型的泛化能力和性能。
3. 知识转移
ViTPose 通过引入简单的知识令牌(knowledge token),实现了知识转移。具体来说,在训练过程中,可以在大型模型中引入一些额外的令牌,这些令牌用于存储中间特征信息。当训练小型模型时,可以通过这些知识令牌将大型模型的知识传递给小型模型,从而提高小型模型的性能。

应用场景
1. 体育运动分析
在体育运动分析中,ViTPose 可以用于实时检测运动员的动作,帮助教练员和运动员分析运动姿态,提高训练效果。例如,在篮球比赛中,ViTPose 可以实时检测球员的投篮动作,分析动作的规范性和准确性,从而提供有针对性的训练建议。
2. 虚拟现实与增强现实
在虚拟现实(VR)和增强现实(AR)应用中,ViTPose 可以用于实时捕捉用户的肢体动作,实现自然的交互体验。例如,在 VR 游戏中,ViTPose 可以实时检测玩家的手部和身体动作,使游戏中的角色能够更自然地响应玩家的操作。
3. 医疗康复
在医疗康复领域,ViTPose 可以用于监测患者的康复进程,帮助医生评估患者的康复情况。例如,在物理治疗中,ViTPose 可以实时检测患者的关节活动范围,评估康复效果,从而制定更有效的康复计划。
4. 人机交互
在人机交互领域,ViTPose 可以用于实现手势识别和姿态控制。例如,在智能家居系统中,ViTPose 可以实时检测用户的姿势和手势,实现对家居设备的智能控制,提高用户体验。
相关链接
GitHub 仓库:https://github.com/ViTAE-Transformer/ViTPose
论文:https://arxiv.org/abs/2206.01278
总结
ViTPose 是一种基于视觉变换器的人体姿态估计模型,其设计理念是利用视觉变换器的强大力量,结合轻量级解码器,实现高效且准确的人体姿态估计。ViTPose 具有简单的模型结构、可扩展的模型大小、灵活的训练范式、知识可转移和优秀的实验结果等优点。在体育运动分析、虚拟现实与增强现实、医疗康复和人机交互等多个应用场景中,ViTPose 均表现出色,具有广泛的应用前景。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2991.html




开源的超长文本生成模型")
















