文本到音频生成(Text-to-Audio Generation, 简称 TTA)作为生成任务的一个子领域,涵盖了音效创作、音乐创作和合成语音,具有广泛的应用潜力。在影视后期制作、电子游戏开发、音频编辑等领域,高质量的文本到音频生成模型能够显著提高工作效率和创作质量。然而,传统的潜在扩散模型(Latent Diffusion Models, LDMs)尽管在多个生成任务中表现卓越,但其迭代采样过程带来了巨大的计算负担,导致生成速度缓慢,限制了它们在实际 TTA 应用中的部署。为了解决这一问题,浙江大学与阿里巴巴联合提出了一种新型的高效高质量文本-音频生成模型——AudioLCM。
一、AudioLCM是什么
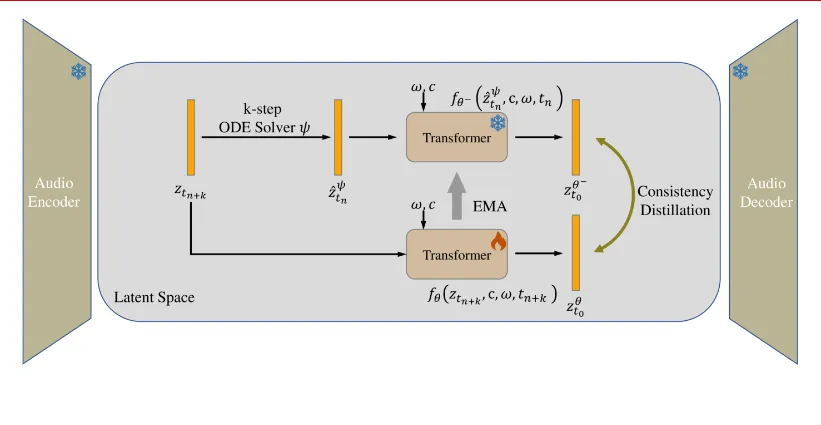
AudioLCM 是一种基于一致性模型(Consistency Models, CMs)和潜在扩散模型(LDMs)的新型文本到音频生成模型。该模型通过集成一致性模型到生成过程中,并引入多步常微分方程(multi-step ODE)求解器的指导一致性蒸馏技术,极大地提高了生成速度和音频质量。同时,AudioLCM 还集成了 LLaMA 开创的先进技术,增强了基于 Transformer 的神经网络架构,进一步提升了模型的性能和训练稳定性。
二、功能特色
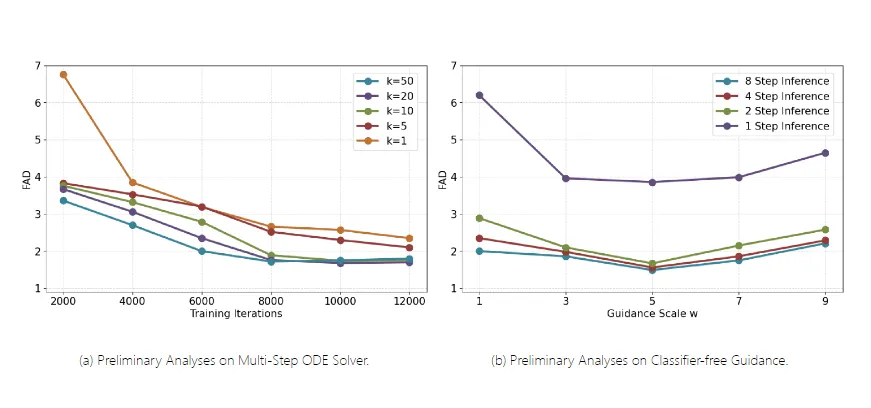
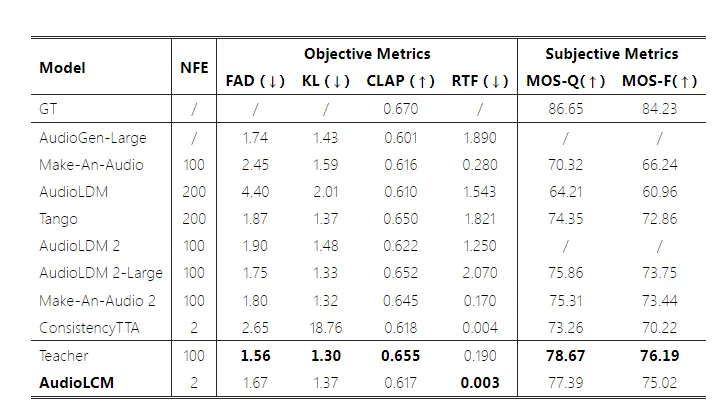
高效生成:AudioLCM 通过集成一致性模型,避免了传统 LDMs 依赖迭代过程去除噪声的缺点,实现了快速推理。实验结果显示,AudioLCM 仅需 2 次迭代即可合成高保真音频,同时保持了与使用数百步的最先进模型竞争的样本质量。在单个 NVIDIA 4090Ti GPU 上,AudioLCM 实现了超越实时 333 倍的采样速度,使生成模型在文本到音频生成部署中实际可行。
高质量输出:AudioLCM 通过引入多步 ODE 求解器进行单阶段的指导一致性蒸馏,克服了 LDMs 固有的收敛问题,减少了迭代步骤,同时保持了样品质量。实验结果显示,AudioLCM 生成的音频样本在频谱和分布上与真实音频的差异最小,证明了其高质量的输出能力。
强大的文本到音频合成性能:AudioLCM 通过集成 LLaMA 的先进技术,增强了基于 Transformer 的神经网络架构,提供了更高的性能和训练稳定性。这使得 AudioLCM 在文本到音频合成任务中表现出色,能够生成自然、准确的音频样本。
易于使用和扩展:AudioLCM 的代码已经开源,用户可以在 GitHub 上获取。仓库中包含了详细的指南和脚本,方便用户快速上手和扩展。同时,AudioLCM 支持多种数据集和预训练模型,用户可以根据需要进行选择和调整。
三、技术细节
一致性模型(CMs)的集成:AudioLCM 通过将一致性模型集成到生成过程中,实现了快速推理。一致性模型通过将任意时间步的任何点映射到轨迹的初始点,避免了因为减少反向迭代导致感知质量显著下降的问题。这使得 AudioLCM 在保持高质量输出的同时,显著提高了生成速度。
多步常微分方程(ODE)求解器的引入:为了克服 LDMs 的收敛问题并减少迭代步骤,AudioLCM 引入了多步 ODE 求解器进行单阶段的指导一致性蒸馏。这项创新在保持样品质量的同时,大幅度缩短了时间步长,从数千步减少到数十步,实现了快速的收敛。
增强的 Transformer-based 骨干网络:AudioLCM 通过集成 LLaMA 的先进技术,增强了基于 Transformer 的神经网络架构。这些技术包括预归一化、旋转嵌入和 SwiGLU 激活等,为量身定制的因果变压器架构提供了更高的性能和训练稳定性。这使得 AudioLCM 在文本到音频合成任务中表现出色。
反向扩散过程的 PF-ODE 重定义:为了减少计算开销并提升性能,AudioLCM 重新定义了反向扩散过程的 PF-ODE。引入一致性函数,将一致性噪声预测模型参数化以满足边界条件。通过利用 DDIM 作为 ODE 求解器在训练时确切估计音频潜在变量的演变,AudioLCM 实现了快速收敛和高质量生成。
四、应用场景
AudioLCM 作为一种高效高质量的文本到音频生成模型,具有广泛的应用场景。以下是几个典型的应用场景:
影视后期制作:在影视后期制作中,AudioLCM 可以用于生成各种音效和音乐。例如,通过输入文本描述,AudioLCM 可以快速生成符合剧情需求的背景音乐和特效音效,提高影视作品的制作效率和质量。
电子游戏开发:在电子游戏开发中,AudioLCM 可以用于生成游戏中的音效和背景音乐。通过输入游戏场景和角色的文本描述,AudioLCM 可以快速生成符合游戏氛围的音效和背景音乐,增强游戏的沉浸感和代入感。
音频编辑:在音频编辑领域,AudioLCM 可以用于生成各种语音样本和音效。例如,通过输入文本描述,AudioLCM 可以快速生成符合需求的语音样本和音效素材,为音频编辑工作提供便利。
语音合成:AudioLCM 还可以用于语音合成领域。通过输入文本描述,AudioLCM 可以生成自然、准确的语音样本,为语音合成技术提供新的解决方案。
六、相关链接
AudioLCM 论文链接:https://arxiv.org/html/2406.00356
AudioLCM 代码仓库链接:https://github.com/liuhuadai/AudioLCM
七、总结
AudioLCM 是一种基于一致性模型和潜在扩散模型的新型文本到音频生成模型。该模型通过集成一致性模型到生成过程中,并引入多步常微分方程求解器的指导一致性蒸馏技术,实现了高效高质量的文本到音频生成。AudioLCM 在影视后期制作、电子游戏开发、音频编辑和语音合成等领域具有广泛的应用前景。随着技术的不断发展和完善,AudioLCM 有望在更多领域发挥重要作用,为文本到音频生成技术的发展带来新的突破。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2974.html



的人体姿态估计模型")
开源的超长文本生成模型")
















