LatentSync是什么
LatentSync是一项由字节跳动联合北京交通大学提出的创新技术,它代表了一种新型的唇部同步框架。该框架基于音频条件潜在扩散模型,旨在实现视频中人物唇部动作与音频的精准同步。与以往基于像素空间扩散或两阶段生成的方法不同,LatentSync采用端到端的方式,无需任何中间运动表示,从而能够更直接和高效地建模复杂的音频与视觉之间的关系。这一技术的推出,标志着唇同步技术在准确性和时间一致性方面迈出了重要的一步。
功能特色
高精度唇同步
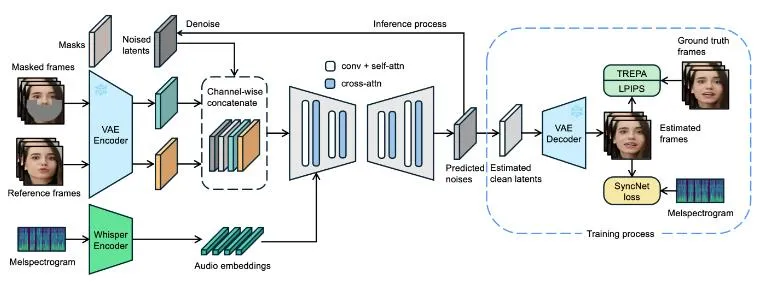
LatentSync通过利用音频条件潜在扩散模型,实现了对唇部动作与音频的精准同步。这一功能的核心在于,它能够将音频信号转换为嵌入表示,并通过交叉注意力层将其集成到U-Net模型中,从而直接生成与音频匹配的唇部动作。这种端到端的设计避免了中间运动表示的需要,减少了误差的累积,提高了唇同步的精确度。
强大的时间一致性
传统基于扩散的唇同步方法在时间一致性方面表现不佳,因为不同帧之间的扩散过程存在不一致性。为了解决这一问题,LatentSync引入了Temporal REPresentation Alignment(TREPA)机制。TREPA利用大型自监督视频模型提取的时间表示,使生成的帧与真实帧对齐,从而增强时间一致性。这一机制确保了生成的视频在唇同步准确性的同时,能够在时间上保持连贯。
高质量视频生成
LatentSync利用Stable Diffusion的强大生成能力,能够生成动态逼真的说话视频。通过优化模型架构、训练超参数和数据预处理方法,LatentSync在HDTF测试集上显著提高了SyncNet的准确率,从91%提升到94%。这一提升不仅提高了唇同步的准确性,还使得生成的视频在视觉质量上达到了新的高度。
广泛的适用性
LatentSync不仅适用于真人拍摄的视频,还适用于动画人物的唇同步。无论是真人还是虚拟角色,LatentSync都能根据音频输入自动调整视频中角色的口型,实现音画同步效果。这一广泛的适用性使得LatentSync在视频制作、虚拟数字人口播、视频翻译对口型等多个领域具有巨大的应用潜力。
技术细节
音频嵌入提取
LatentSync使用预训练的音频特征提取器Whisper将音频频谱图转换为音频嵌入。Whisper是一种基于Transformer的模型,能够高效地将音频信号转换为高维的嵌入表示。这些嵌入表示包含了音频的语义信息,为后续的唇同步处理提供了重要的输入。
U-Net模型集成
将音频嵌入集成到U-Net模型中,是LatentSync实现唇同步的关键步骤。U-Net是一种经典的卷积神经网络架构,具有强大的图像生成能力。在LatentSync中,U-Net模型接收参考帧和掩码帧作为输入,并通过交叉注意力层将音频嵌入集成到模型中。这一过程使得模型能够学习到音频与视觉之间的复杂关系,从而生成与音频匹配的唇部动作。
单步训练过程
LatentSync的训练过程采用单步方法,从预测的噪声中快速获取估计的清晰潜在表示。这一方法避免了传统扩散模型在训练过程中需要多次迭代的问题,提高了训练效率。同时,通过优化模型架构和训练超参数,LatentSync能够在保证唇同步准确性的同时,生成高质量的视频。
TREPA机制
TREPA是LatentSync中用于增强时间一致性的关键技术。它利用大型自监督视频模型提取的时间表示,使生成的帧与真实帧对齐。具体来说,TREPA通过计算生成帧和真实帧之间的时间表示距离作为额外损失,从而引导模型在训练过程中更加注重时间一致性。这一机制确保了生成的视频在唇同步准确性的同时,能够在时间上保持连贯。
应用场景
视频制作
在视频制作领域,LatentSync可以用于实现角色口型与音频的精准同步。无论是真人还是虚拟角色,LatentSync都能根据音频输入自动调整角色的口型,使得视频更加逼真和流畅。这一功能对于电影、电视剧、广告等视频内容的制作具有重要意义。
虚拟数字人口播
随着虚拟数字人的普及,虚拟数字人口播成为了一个重要的应用领域。LatentSync可以根据音频输入自动生成虚拟数字人的唇部动作,实现音画同步效果。这一功能使得虚拟数字人在播报新闻、讲解知识、互动娱乐等方面具有更高的真实感和互动性。
视频翻译对口型
在视频翻译领域,LatentSync可以用于实现源语言视频与目标语言视频之间的口型同步。通过将源语言视频中的音频替换为目标语言音频,并使用LatentSync调整目标语言视频中的角色口型,可以实现更加自然和流畅的视频翻译效果。这一功能对于跨语言视频内容的传播和交流具有重要意义。
相关链接
开源地址:LatentSync项目主页
论文链接:LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
ComfyUI插件地址:ComfyUI-LatentSyncWrapper插件地址
FFmpeg下载地址:FFmpeg下载地址
总结
LatentSync作为一种新型的唇同步框架,基于音频条件潜在扩散模型实现了对唇部动作与音频的精准同步。通过利用Whisper提取音频嵌入、U-Net模型集成、单步训练过程以及TREPA机制等关键技术,LatentSync在唇同步准确性、时间一致性、视频生成质量以及广泛适用性等方面均表现出色。随着虚拟数字人、视频翻译等领域的不断发展,LatentSync的应用前景将更加广阔。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2887.html



的人体姿态估计模型")

开源的超长文本生成模型")















