随着人工智能技术的不断发展,生成式语言模型在各个领域的应用日益广泛。然而,这些模型在从训练到实际应用的过程中面临着诸多挑战。其中,如何在推理阶段使模型达到最佳表现是一个亟待解决的问题。谷歌DeepMind和谷歌研究团队推出的InfAlign框架,正是为了解决这一难题而诞生的。
InfAlign是什么
InfAlign是一个旨在提升语言模型推理对齐能力的机器学习框架。它通过将推理时的方法纳入对齐过程,力求弥补训练与应用之间的鸿沟。传统的对齐方法往往忽视了推理时的解码策略,如Best-of-N采样和控制解码,这可能导致效率低下,影响输出的质量和可靠性。而InfAlign则通过一种校准的强化学习方法来调整基于特定推理策略的奖励函数,从而实现训练目标与推理需求的对齐。
功能特色
推理感知对齐
InfAlign的核心功能是实现推理感知的对齐。传统的对齐方法通常关注于提高模型的胜率,但往往忽视了推理时的解码策略。而InfAlign则通过考虑推理时的解码过程,优化对齐模型在推理时的表现。这使得对齐后的模型不仅能够在训练环境中表现出色,还能够在现实场景中保持一致的高性能。
灵活的推理策略支持
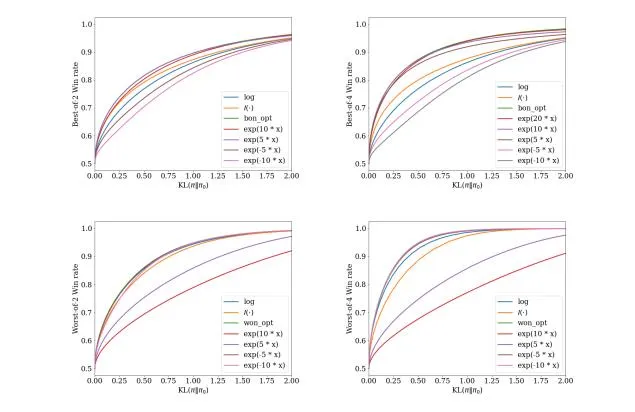
InfAlign支持多种推理策略,如Best-of-N采样和Worst-of-N采样等。通过针对这些策略进行特定的奖励函数调整,InfAlign能够确保模型在控制环境和现实场景中都能表现出色。这种灵活性使得InfAlign能够适应不同的应用场景和需求。
高效的校准与变换强化学习
InfAlign采用了一种高效的校准与变换强化学习(CTRL)算法。该算法遵循三个步骤:校准奖励分数、根据推理策略变换这些分数、解决一个KL正则化的优化问题。通过将奖励变换定制化到特定场景,InfAlign能够显著提升模型的推理胜率,同时保持计算效率。
增强的鲁棒性
InfAlign增强了模型的鲁棒性,使其能够有效应对各种解码策略,并产生一致的高质量输出。这意味着即使面对不同的推理场景和需求,InfAlign对齐后的模型也能够保持稳定的性能表现。
技术细节
CTRL算法
CTRL算法是InfAlign的核心。它遵循三个关键步骤:
校准奖励分数:首先,对模型的奖励分数进行校准,以确保它们能够准确反映模型在推理时的表现。
根据推理策略变换奖励分数:然后,根据所选的推理策略(如Best-of-N采样或Worst-of-N采样)对奖励分数进行变换。这一步骤旨在使奖励函数与推理策略相匹配,从而优化模型在推理时的表现。
解决KL正则化的优化问题:最后,通过解决一个KL正则化的优化问题,进一步调整奖励函数,以确保对齐后的模型既能够保持高性能,又具有良好的泛化能力。
推理策略支持
InfAlign特别支持两种重要的推理策略:
Best-of-N采样:从模型中生成多个响应,并选择其中最佳的一个作为输出。这种策略在需要高准确性的场景中非常有用。
Worst-of-N采样:与Best-of-N采样相反,Worst-of-N采样选择最差的响应作为输出。这种策略在需要评估模型最坏情况下的性能时非常有用,常用于安全评估等场景。
应用场景
InfAlign的应用场景非常广泛,涵盖了自然语言处理、计算机视觉、智能助手等多个领域。以下是一些具体的应用场景示例:
自然语言处理
在自然语言处理领域,InfAlign可以用于提升生成式语言模型的推理对齐能力。例如,在对话系统、文本生成和机器翻译等任务中,InfAlign可以确保模型在推理时能够产生准确、流畅且符合语境的输出。
计算机视觉
在计算机视觉领域,InfAlign可以用于提升图像生成模型的性能。通过优化推理时的解码策略,InfAlign可以确保生成的图像不仅具有高分辨率和逼真感,还能够准确响应复杂的文本指令。
智能助手
在智能助手领域,InfAlign可以用于提升语音助手和自然语言处理助手的性能。通过优化推理时的对齐过程,InfAlign可以确保助手在回答用户问题时能够产生准确、有用且无害的输出。
安全评估
在安全评估领域,InfAlign可以用于评估模型在最坏情况下的性能。通过采用Worst-of-N采样策略,InfAlign可以识别出模型可能存在的漏洞和弱点,从而帮助开发者进行改进和优化。

相关链接
DeepMind官网:https://deepmind.com/
InfAlign论文链接:https://arxiv.org/abs/2412.19792
总结
InfAlign是一个旨在提升语言模型推理对齐能力的机器学习框架。它通过将推理时的方法纳入对齐过程,实现了训练目标与推理需求的对齐。InfAlign采用了一种高效的校准与变换强化学习(CTRL)算法,支持多种推理策略,并显著增强了模型的鲁棒性。在自然语言处理、计算机视觉、智能助手和安全评估等多个领域,InfAlign都展现出了广泛的应用前景。通过不断优化和改进,InfAlign有望成为未来生成式语言模型训练和应用的重要工具之一。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2864.html





















