在深度学习领域,优化器的选择对于模型的训练效率和最终性能至关重要。Adam(Adaptive Moment Estimation)作为一种广泛应用的优化算法,因其结合了动量法和RMSprop的优点,能够自适应地调整每个参数的学习率,从而在多种任务上表现出色。然而,传统的Adam优化器在权重衰减(Weight Decay)的处理上存在一些问题,这可能导致模型在训练过程中出现不稳定或泛化能力下降的情况。为了解决这一问题,Loshchilov和Hutter提出了AdamW优化器,通过将权重衰减与梯度更新解耦,改进了Adam的性能。而在此基础上,本文将进一步介绍一种名为C-AdamW(Cautious AdamW)的优化器,它在保持AdamW优点的同时,通过谨慎的参数更新策略,进一步提升了训练效率和模型性能。
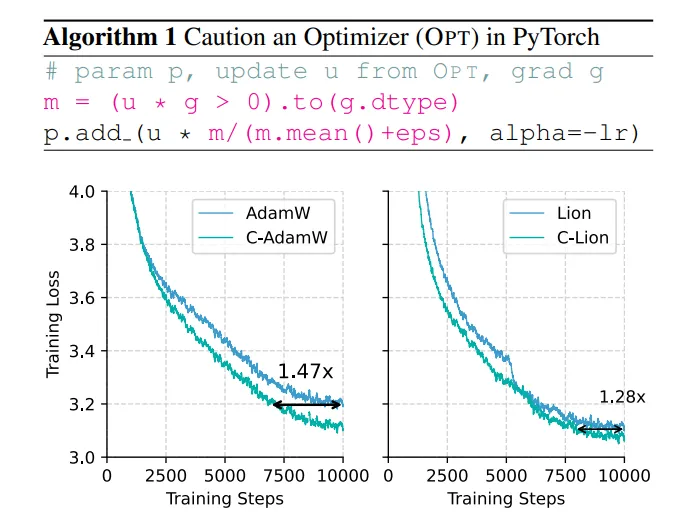
C-AdamW是什么
C-AdamW是AdamW优化器的一种改进版本,属于谨慎优化器(Cautious Optimizer)家族的一员。其核心思想是在AdamW的基础上,通过一种简单的修改,使得优化器在参数更新过程中更加谨慎,减少不必要的震荡,从而加速收敛并提高模型的泛化能力。具体来说,C-AdamW在保持AdamW自适应学习率和独立权重衰减优点的同时,通过调整动量项或梯度项的计算方式,使得参数更新更加平稳和高效。
功能特色
1. 自适应学习率与独立权重衰减
C-AdamW继承了AdamW的核心优势,即自适应学习率和独立权重衰减。自适应学习率允许优化器根据每个参数的历史梯度信息动态调整学习率,从而在训练过程中自动适应不同参数的学习需求。独立权重衰减则将权重衰减项从梯度更新中解耦出来,单独处理,避免了传统Adam中权重衰减与动量更新机制耦合导致的问题,使得模型在训练过程中更加稳定,且能有效防止过拟合。
2. 谨慎的参数更新策略
C-AdamW通过引入谨慎的参数更新策略,进一步提升了优化器的性能。这种策略的核心在于减少不必要的参数更新震荡,使得参数在更新过程中更加平滑地收敛到最优值。具体来说,C-AdamW可能通过调整动量项的计算方式(如引入衰减因子或调整动量衰减率),或者对梯度项进行某种形式的预处理(如梯度裁剪或平滑处理),以实现谨慎的参数更新。
3. 加速收敛与提高泛化能力
由于C-AdamW采用了谨慎的参数更新策略,它在训练过程中能够更快地收敛到最优解,并且由于减少了不必要的震荡,模型的泛化能力也得到提升。这意味着使用C-AdamW训练的模型在测试集上的表现通常会更好,能够更准确地泛化到新数据上。
4. 易于实现与兼容性
C-AdamW的实现相对简单,通常只需在现有AdamW代码的基础上进行少量修改即可。同时,由于它保持了AdamW的基本框架和接口,因此与现有的深度学习框架(如PyTorch、TensorFlow等)具有良好的兼容性,可以方便地集成到各种深度学习模型中。

技术细节
1. C-AdamW的算法流程
C-AdamW的算法流程大致可以分为以下几个步骤:
初始化参数:设定学习率η、动量衰减率β1、动量平方的衰减率β2、权重衰减系数λ以及一个小常数ϵ(用于防止除零错误)。
前向传播与反向传播:计算模型在当前批次数据上的前向传播结果和反向传播梯度。
一阶动量和二阶动量估计:根据当前梯度和历史动量信息,计算一阶动量(梯度的移动平均)和二阶动量(梯度平方的移动平均)。在C-AdamW中,这一步可能会引入谨慎更新策略的调整。
偏差校正:对一阶动量和二阶动量进行偏差校正,以消除初始阶段的偏差影响。
参数更新:根据一阶动量、二阶动量、学习率和权重衰减系数更新模型参数。在C-AdamW中,权重衰减项是独立处理的,不再与梯度更新耦合在一起。
2. 谨慎更新策略的实现
C-AdamW中的谨慎更新策略可能通过以下几种方式实现:
动量衰减调整:通过引入额外的衰减因子或调整动量衰减率β1,使得动量项在更新过程中逐渐减小,从而减少震荡。
梯度裁剪:对梯度进行裁剪处理,限制其最大值,以防止梯度爆炸导致的参数更新过大。
梯度平滑:对梯度进行平滑处理(如使用移动平均或低通滤波),以减少梯度中的噪声成分,使得参数更新更加平稳。
需要注意的是,具体的谨慎更新策略可能因实现而异,不同的实现方式可能会对优化器的性能产生不同的影响。
应用场景
C-AdamW作为一种高效且稳健的深度学习优化器,适用于多种应用场景。以下是一些典型的应用场景示例:
1. 自然语言处理
在自然语言处理(NLP)任务中,如文本分类、情感分析、机器翻译等,C-AdamW可以显著提升模型的训练效率和性能。由于NLP任务通常涉及大量的文本数据和复杂的模型结构,因此选择一种合适的优化器对于提高模型性能至关重要。C-AdamW通过其自适应学习率和谨慎的参数更新策略,能够加速模型收敛并提高泛化能力,从而在这些任务上表现出色。
2. 计算机视觉
在计算机视觉(CV)任务中,如图像分类、目标检测、语义分割等,C-AdamW同样具有广泛的应用前景。这些任务通常需要处理大量的图像数据和高维的特征表示,对模型的训练效率和性能提出了较高的要求。C-AdamW通过其高效的优化算法和稳健的参数更新策略,能够帮助模型更快地收敛到最优解,并提高在测试集上的表现。
3. 推荐系统
在推荐系统领域,C-AdamW也可以发挥重要作用。推荐系统通常需要处理海量的用户数据和商品信息,以实现对用户兴趣的精准预测和个性化推荐。使用C-AdamW优化器可以加速推荐模型的训练过程,并提高模型的预测准确性和泛化能力,从而为用户提供更加个性化和精准的推荐服务。
总结
C-AdamW作为一种基于AdamW的谨慎优化器,通过引入谨慎的参数更新策略,进一步提升了优化器的性能和稳定性。它在保持AdamW自适应学习率和独立权重衰减优点的同时,通过减少不必要的参数更新震荡,加速了模型的收敛过程并提高了泛化能力。在多种深度学习应用场景中,C-AdamW都展现出了出色的表现,为模型的训练和性能提升提供了有力的支持。随着深度学习技术的不断发展和应用场景的不断拓展,我们有理由相信C-AdamW将在未来发挥更加重要的作用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2449.html















