SPIRIT LM是什么
SPIRIT LM(Spirit Language Model),由Meta AI团队开发并开源,是一款具有里程碑意义的多模态大语言模型。不同于传统语言模型主要聚焦于单一模态(如纯文本)的处理,SPIRIT LM能够自由混合并理解文本和语音数据,实现跨模态的自然交互。这一突破不仅标志着人工智能在音频与文本结合领域的重大进步,也为未来智能交互技术的发展奠定了坚实基础。
功能特色
1. 多模态处理能力
SPIRIT LM的核心功能在于其多模态处理能力。该模型能够无缝地处理和生成文本与语音数据,实现两者之间的自由转换。无论是从文本到语音,还是从语音到文本,SPIRIT LM都能提供高质量的生成结果,且能够保持语义和情感的一致性。
2. 情感与风格捕捉
SPIRIT LM不仅理解语言的字面意义,还能捕捉并再现说话者的音调、情感和风格。这一特性使得生成的语音更加生动自然,能够更好地模拟人类对话中的情感表达。这对于提升人机交互的真实感和用户体验具有重要意义。
3. 少量样本学习能力
SPIRIT LM具备强大的少量样本学习能力。在少量样本的情况下,该模型能够迅速学习新任务,如自动语音识别(ASR)、文本转语音(TTS)和语音分类等。这种灵活性使得SPIRIT LM能够广泛应用于各种实际场景,满足不同领域的需求。
4. 高效的模型架构
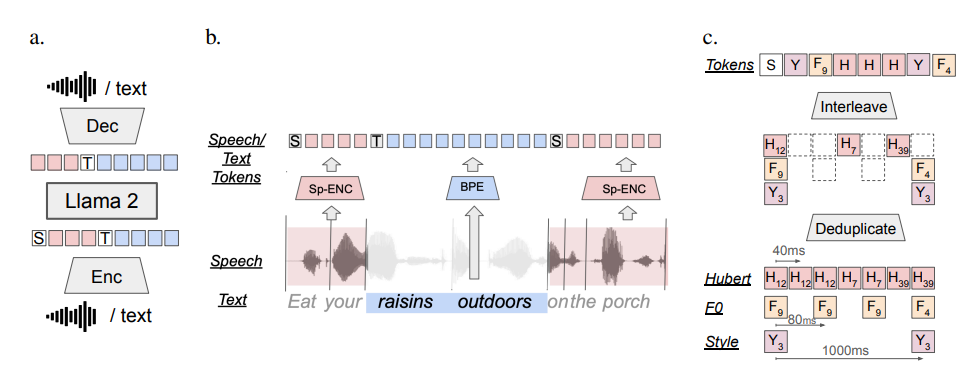
SPIRIT LM的模型架构简洁而高效。它采用基于令牌的方法将语音和文本结合起来,通过交错的训练方式提升模型在跨模态任务上的表现。此外,SPIRIT LM还提供了基础版和表达版两个版本,以满足不同场景下的需求。
技术细节
1. 模型架构
SPIRIT LM基于预训练的文本语言模型构建,通过在文本和语音单元上的持续训练扩展到语音模态。该模型将语音和文本序列连接成一个单一的标记集,并使用一个小型自动管理的语音-文本平行语料库进行训练。这种设计使得模型能够在生成和理解文本与语音之间无缝切换。
2. 训练方法
SPIRIT LM的训练采用了词级交错方法,将语音数据通过HuBERT预处理系统转换成语音单元的集群,然后与文本令牌结合,形成交错的语音-文本序列。这种交错训练方式有助于模型学习语音和文本之间的对应关系,提升跨模态任务的性能。
3. 表达版特色
SPIRIT LM的表达版在基础版的基础上增加了音高和风格单元,以模拟语音的表达性。通过音高和风格标记的引入,表达版能够生成更具人情味的语音,进一步提升用户体验。同时,表达版还依赖于专门的语音合成器(如HifiGAN声码器)和时长预测模块,以确保生成的语音波形在音调和节奏上与自然语音保持一致。
4. 语义与表达能力
SPIRIT LM结合了文本模型的语义能力和语音模型的表达能力,使得模型在生成文本和语音时既能保持语义的一致性,又能展现丰富的表达性。这种平衡的设计使得SPIRIT LM在多种应用场景下都能表现出色。
应用场景
1. 语音助手
SPIRIT LM为语音助手提供了强大的技术支持。通过理解和生成高质量的语音与文本内容,SPIRIT LM能够提升语音助手的智能化水平,使其能够更好地理解用户需求并提供个性化的服务。
2. 教育领域
在教育领域,SPIRIT LM可以应用于智能教育助手的开发。通过生成带有情感色彩的音频讲解,SPIRIT LM能够为学生提供更加生动、有趣的学习体验。同时,该模型还可以根据学生的反馈调整教学策略,实现个性化的教学服务。
3. 娱乐产业
在娱乐产业中,SPIRIT LM可以用于游戏角色的声音生成。通过捕捉和再现角色的情感和风格,SPIRIT LM能够为游戏角色赋予更加生动的声音表现,提升玩家的沉浸感和游戏体验。
4. 客户服务
在客户服务领域,SPIRIT LM可以应用于基于情感识别的客服助手开发。通过识别客户的情感状态并提供相应的回应策略,SPIRIT LM能够显著提升客户服务的质量和效率。
相关链接
SPIRIT LM官方网站:https://speechbot.github.io/spiritlm/
论文地址:https://arxiv.org/pdf/2402.05755
总结
SPIRIT LM作为Meta AI团队开发并开源的多模态大语言模型,在音频与文本处理领域展现了巨大的潜力。它不仅具备强大的多模态处理能力、情感与风格捕捉能力以及少量样本学习能力,还提供了高效的模型架构和丰富的应用场景。随着技术的不断发展和完善,SPIRIT LM有望在更多领域发挥重要作用,推动智能交互技术的广泛普及和应用。未来,我们期待SPIRIT LM能够在提升用户体验、推动产业发展等方面发挥更加积极的作用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2388.html



的人体姿态估计模型")

开源的超长文本生成模型")















