在人工智能技术飞速发展的今天,实时语音交互已成为人们日常生活的重要组成部分。Ultravox,一款由FixieAI公司开发的创新性多模态大语言模型,旨在提供一个封闭源模型如 GPT-4的替代方案。Ultravox最新v0.4.1版本不仅关注语言能力,还着重于在不同媒体类型之间实现流畅、具有上下文意识的对话。
一、Ultravox是什么
Ultravox是一款开源的多模态大语言模型(LLM),它能够直接理解文本和人类语音,无需经过单独的语音识别阶段。这款模型的独特之处在于其多模态设计,它能够将音频信号直接映射到高维空间,与Llama3模型使用的表示空间相同,从而实现实时语音交互。

二、功能特色
多模态交互:Ultravox能够同时处理文本和语音输入,为用户提供更加自然和流畅的交互体验。
无需ASR阶段:传统的语音交互系统需要先将语音转换为文本,再进行处理。Ultravox省略了这一步骤,直接处理语音嵌入,大大提高了响应速度。
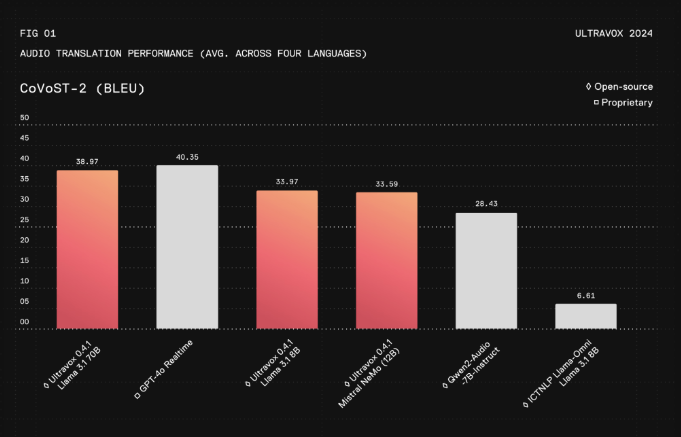
高效性能:根据官方数据,Ultravox v0.3版本在处理音频内容时,首个token的生成时间(TTFT)约为150毫秒,每秒可生成约60个token,表现出卓越的性能。
基于Llama3模型:Ultravox基于Meta公司的Llama3模型构建,通过添加一个多模态投影器来扩展其功能,使其在处理速度和理解能力上都有显著优势。
开源与定制:Ultravox的开源特性允许用户根据自己的需求进行定制和优化,满足不同场景下的应用需求。
三、技术细节
模型架构:Ultravox的核心创新在于其多模态设计。它将音频信号映射到高维空间,与Llama3模型使用的表示空间相同,实现了音频和文本的统一处理。
多模态投影器:Ultravox通过添加一个多模态投影器来扩展Llama3模型的功能。这个投影器能够将音频直接转换为Llama3使用的高维空间表示。
性能指标:Ultravox v0.3版本在处理音频内容时,首个token的生成时间约为150毫秒,每秒可生成约60个token,这些性能指标是基于Llama3.18B骨干网络实现的。
四、应用场景
语音助手:Ultravox可以应用于智能语音助手,为用户提供实时、自然的语音交互体验。
客户服务:在客户服务领域,Ultravox可以替代传统的自动语音识别系统,提供更加高效和准确的语音理解能力。
教育应用:在教育领域,Ultravox可以帮助学生通过语音交互学习新知识,提高学习效率。
智能家居:在智能家居系统中,Ultravox可以控制各种设备,为用户提供便捷的语音控制体验。
娱乐互动:在游戏和娱乐应用中,Ultravox可以实现更加真实的语音交互,提升用户体验。
五、相关链接
Ultravox官网介绍:点击进入
六、总结
Ultravox作为一款开源的多模态大语言模型,以其独特的多模态设计、高效的性能和广泛的应用场景,正引领着实时语音交互领域的新纪元。它的开源特性为用户提供了极大的灵活性和定制空间,使其成为人工智能领域的一个重要创新。随着技术的不断发展和优化,Ultravox有望在未来实现更多突破性的应用,为人们的生活带来更多便利和惊喜。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2301.html





的人体姿态估计模型")















