
什么是Fluid?
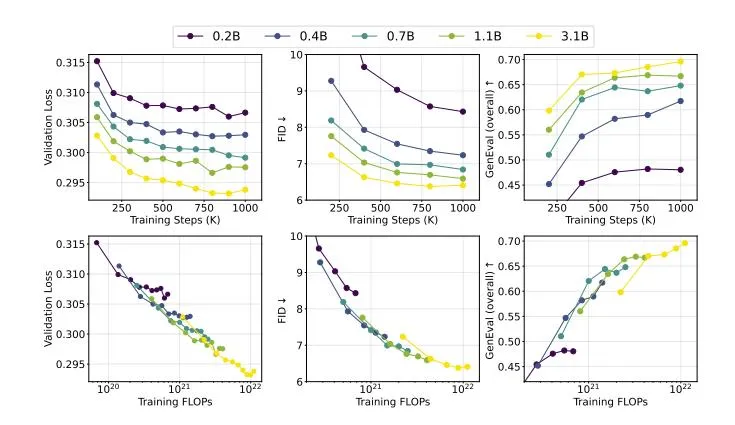
Fluid是由Google DeepMind和MIT联合开发的一款先进的文本到图像生成模型。它通过自回归生成方法,结合连续标记和随机生成顺序的技术,实现了在视觉质量和评估性能上的显著提升。在10.5亿参数规模下,Fluid在MS-COCO数据集上达到了6.16的零样本FID得分,并在GenEval基准测试中获得了0.69的高分,刷新了文生图领域的纪录。
随着深度学习技术的快速发展,文本到图像生成模型逐渐成为研究热点。从早期的GAN(生成对抗网络)到后来的VQ-VAE(向量量化变分自编码器),再到现在的Transformer架构,这些模型在图像生成的质量和多样性上不断取得突破。然而,现有的模型在处理复杂场景和长距离依赖关系时仍存在一些局限性。Fluid正是在这一背景下应运而生,旨在通过创新的技术手段解决这些问题。
功能特色
文本到图像生成
Fluid的核心功能是根据给定的文本提示生成相应的图像。用户只需输入一段描述性的文字,Fluid就能生成一张高质量的图像。这一功能在多个领域具有广泛的应用前景,如艺术创作、广告设计、影视制作等。
连续标记使用
传统的文本到图像生成模型在处理文本输入时,通常会将文本分割成离散的标记。这种方法虽然简单,但容易导致信息丢失,影响生成图像的质量。Fluid引入了连续标记的概念,通过将文本嵌入到连续的向量空间中,减少了信息损失,提高了图像生成的精度和质量。
随机顺序生成
传统的自回归生成模型通常按照固定的顺序生成图像,这可能导致生成的图像缺乏全局结构和上下文信息。Fluid采用随机顺序生成机制,即在生成过程中不遵循固定的顺序,而是随机选择生成的位置。这种机制有助于更好地捕捉图像的全局结构,提高生成图像的真实感和自然度。
自回归建模
自回归建模是一种常见的生成模型方法,通过逐步预测序列中的下一个元素,构建与文本提示相匹配的图像。Fluid采用了基于Transformer的自回归建模方法,能够捕捉长距离依赖关系,增强不同部分之间的联系,从而生成更加连贯和自然的图像。
基于Transformer的架构
Transformer架构最初应用于自然语言处理领域,因其强大的并行计算能力和对长距离依赖关系的捕捉能力而受到广泛关注。Fluid借鉴了Transformer的成功经验,将其应用于图像生成任务中。通过多头自注意力机制和前馈神经网络,Fluid能够高效地处理大规模的图像数据,生成高质量的图像。
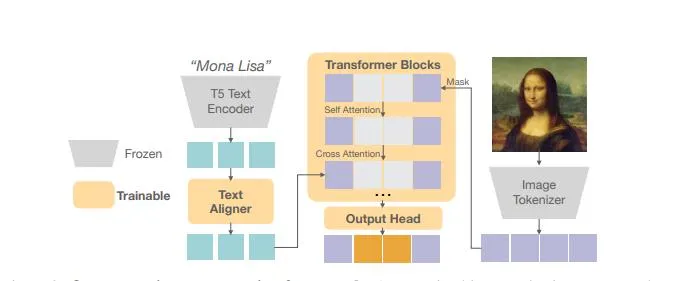
技术细节
模型架构
Fluid的模型架构主要包括以下几个部分:
编码器:负责将输入的文本提示转换为连续的向量表示。编码器采用了Transformer架构,通过多头自注意力机制和前馈神经网络,捕捉文本中的语义信息。
解码器:负责根据编码器生成的向量表示,逐步生成图像。解码器同样采用了Transformer架构,通过自回归建模方法,逐步预测图像中的每个像素值。
连续标记:在编码器和解码器之间,Fluid引入了连续标记机制,将文本嵌入到连续的向量空间中,减少信息损失,提高生成图像的质量。
随机顺序生成:在解码器生成图像的过程中,Fluid采用随机顺序生成机制,不遵循固定的顺序,而是随机选择生成的位置,有助于更好地捕捉图像的全局结构。
训练方法
Fluid的训练方法主要包括以下几个步骤:
数据准备:使用MS-COCO数据集作为训练数据,该数据集包含大量的图像和对应的文本描述。
预训练:首先对编码器和解码器进行预训练,使其能够有效地捕捉文本和图像中的特征。
微调:在预训练的基础上,对模型进行微调,以适应特定的任务需求。微调过程中,通过优化目标函数,使生成的图像与文本提示更加匹配。
评估:使用FID(Fréchet Inception Distance)和GenEval等指标对生成的图像进行评估,确保模型的性能达到预期。
创新点
连续标记:通过将文本嵌入到连续的向量空间中,减少信息损失,提高生成图像的质量。
随机顺序生成:不遵循固定的顺序生成图像,有助于更好地捕捉图像的全局结构。
基于Transformer的架构:利用Transformer的强大并行计算能力和对长距离依赖关系的捕捉能力,生成高质量的图像。
应用场景
艺术创作
Fluid在艺术创作领域具有广泛的应用前景。艺术家可以使用Fluid生成独特的图像和艺术作品,加速创作过程。例如,艺术家可以通过输入一段描述性的文字,生成一张符合创意要求的图像,从而节省大量时间和精力。
媒体和娱乐
在媒体和娱乐领域,Fluid可以用于快速生成概念艺术、背景场景或角色设计,提高前期制作效率。电影制片人和游戏开发者可以使用Fluid生成高质量的图像,用于宣传海报、预告片或游戏场景的设计。
广告和营销
在广告和营销领域,Fluid可以帮助设计师快速生成广告图像和营销材料,实现创意构思。例如,广告公司可以通过输入一段描述性的文字,生成一张符合品牌风格的广告图像,从而提高广告的效果和吸引力。
教育和研究
在教育和研究领域,Fluid可以作为教学工具和科研工具,帮助学生和研究人员理解和可视化复杂概念。例如,教师可以使用Fluid生成科学实验的示意图,帮助学生更好地理解实验过程;研究人员可以使用Fluid生成复杂的数学公式或物理模型的图像,辅助研究工作。
内容创作自动化
在内容创作自动化领域,Fluid可以自动生成图像内容,提高内容生产的效率和吸引力。例如,新闻网站可以使用Fluid生成新闻报道的配图,提高文章的可读性和吸引力;社交媒体平台可以使用Fluid生成用户发布的内容的配图,增强用户体验。

总结
Fluid是一款由Google DeepMind和MIT联合开发的先进文本到图像生成模型。通过自回归生成方法,结合连续标记和随机生成顺序的技术,Fluid在视觉质量和评估性能上取得了显著进展。其主要功能包括文本到图像生成、连续标记使用、随机顺序生成、自回归建模和基于Transformer的架构。Fluid在艺术创作、媒体和娱乐、广告和营销、教育和研究以及内容创作自动化等多个领域具有广泛的应用前景。未来,随着技术的不断发展,Fluid有望在更多领域发挥重要作用,推动图像生成技术的发展和应用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2233.html



的人体姿态估计模型")

开源的超长文本生成模型")















