什么是Seed-ASR?
背景与动机
现代ASR系统通常采用端到端模型,通过深度学习技术直接从音频信号中提取特征并生成文本。然而,这些模型在处理多样化的语音信号时,如不同的领域、语言、口音等,往往表现不佳。为了解决这一问题,研究者们开始探索如何利用大型语言模型(LLM)的强大能力来提升ASR系统的性能。
定义与架构
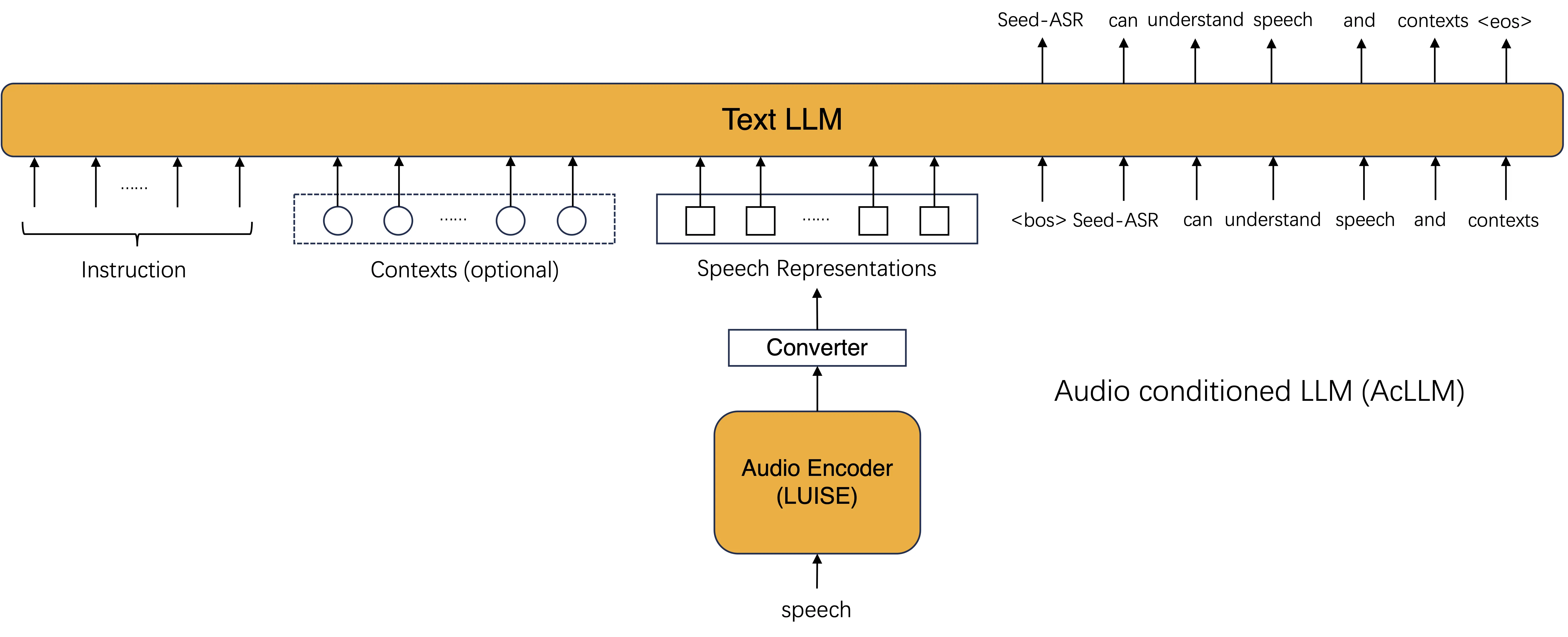
Seed-ASR是字节跳动推出的一款基于大型语言模型(LLM)的语音识别模型。它采用了音频条件下的大型语言模型(AcLLM)框架,通过输入连续的语音表示和上下文信息到LLM中,利用LLM的上下文感知能力和强大的语言建模能力,从而实现更准确的语音识别。Seed-ASR的主要创新点在于将音频信号和上下文信息无缝集成到LLM中,通过大规模分阶段训练,激发LLM的潜在能力,从而在多个领域的评估集中表现出显著改进。
功能特色
多样化语音信号处理
Seed-ASR能够处理来自不同领域、语言、口音和方言的多样化语音信号。无论是在医疗、教育、金融等专业领域,还是在日常对话、新闻播报等通用场景,Seed-ASR都能表现出色。
上下文感知能力
传统的ASR模型在处理长句子或复杂语境时,往往容易出现错误。Seed-ASR通过引入上下文信息,增强了模型的上下文感知能力,能够更好地理解语音信号的语义,从而提高识别准确率。
大规模分阶段训练
Seed-ASR采用了大规模分阶段训练策略,通过逐步增加训练数据的复杂度,逐步提升模型的性能。这种训练方式不仅提高了模型的鲁棒性,还使其在面对未知数据时具有更好的泛化能力。
无需额外语言模型
传统的ASR系统通常需要结合额外的语言模型来提升性能。而Seed-ASR通过将音频信号和上下文信息直接输入到LLM中,实现了端到端的语音识别,无需额外的语言模型,简化了系统架构,降低了部署成本。
技术细节
音频条件下的大型语言模型(AcLLM)
AcLLM是Seed-ASR的核心技术之一。在AcLLM框架下,音频信号被转换为连续的语音表示,然后与上下文信息一起输入到LLM中。具体来说,音频信号首先通过声学模型(如卷积神经网络)提取特征,生成连续的语音表示;然后,这些语音表示与上下文信息(如前文已识别的文本)一起作为输入,送入LLM中进行解码,生成最终的文本输出。
大规模分阶段训练
Seed-ASR采用了大规模分阶段训练策略,主要包括以下几个阶段:
预训练阶段:使用大规模无标注数据对LLM进行预训练,使其具备基本的语言理解和生成能力。
微调阶段:使用带有标注的语音数据对预训练的LLM进行微调,使其适应特定的语音识别任务。
增强训练阶段:通过引入更多的多样化数据(如不同领域的语音数据、不同口音的数据等),进一步提升模型的鲁棒性和泛化能力。
上下文感知能力的激发
为了激发LLM的上下文感知能力,Seed-ASR在训练过程中引入了多种上下文信息,如前文已识别的文本、当前说话人的身份信息等。这些上下文信息有助于模型更好地理解语音信号的语义,从而提高识别准确率。
应用场景
专业领域
Seed-ASR在专业领域的应用非常广泛,如医疗、教育、金融等。在医疗领域,Seed-ASR可以帮助医生快速记录病历,提高工作效率;在教育领域,Seed-ASR可以用于自动批改口语作业,减轻教师的工作负担;在金融领域,Seed-ASR可以用于自动转录电话会议,方便后续分析。
日常生活
在日常生活中,Seed-ASR也有着广泛的应用。例如,智能家居设备可以通过Seed-ASR实现语音控制,提高用户体验;智能客服系统可以通过Seed-ASR实现自动应答,提高服务效率;车载导航系统可以通过Seed-ASR实现语音导航,提高驾驶安全性。
媒体与娱乐
在媒体与娱乐领域,Seed-ASR同样有着重要的应用。例如,新闻播报可以通过Seed-ASR实现自动转录,方便观众阅读;电影字幕可以通过Seed-ASR自动生成,提高制作效率;在线教育平台可以通过Seed-ASR实现自动字幕,提高学习体验。
相关官方链接
项目主页:Seed-ASR官方网站
论文链接:Seed-ASR论文
总结
Seed-ASR作为一种基于大型语言模型的语音识别模型,通过引入音频条件下的大型语言模型(AcLLM)框架,结合大规模分阶段训练和上下文感知能力的激发,实现了在多个领域的显著改进。无论是专业领域、日常生活还是媒体与娱乐,Seed-ASR都展现出了强大的性能和广泛的应用前景。未来,随着技术的不断进步,Seed-ASR有望在更多领域发挥重要作用,为人们的生活带来更多的便利和智能化体验。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2222.html
的多智能体人格模拟工具")




















