最近,字节跳动放出了一个音乐创作的新玩意,叫 Seed-Music。这个神奇的音乐生成模型,可以让你通过多种输入方式(比如文字描述、音频参考、乐谱、甚至语音提示)轻松生成和音乐,简直就像拥有一个音乐魔法师!

Seed-Music 结合了自回归语言模型和扩散模型,不仅能够生成高质量的音乐作品,还能让你对音乐的细节进行精确控制。无论你是想歌词配乐,还是想改编旋律,这里统统没问题。甚至,你可以上传一段短小的语音片段,系统会自动将它转化为完整的歌声,方便又高效。
功能强大的 Seed-Music 不仅支持声乐和器乐的生成,还包括了歌声合成、歌声转换和音乐编辑等一系列功能,能够满足不同用户的需求。你可以通过简单的文本描述生成流行乐,也能通过音频提示调整音乐风格,真是让人耳目一新。
更有趣的是,Seed-Music 的架构分为三个模块:表示学习模块、生成模块和渲染模块,这些模块像乐队一样齐心协力,通过多模态输入生成高质量的音乐。
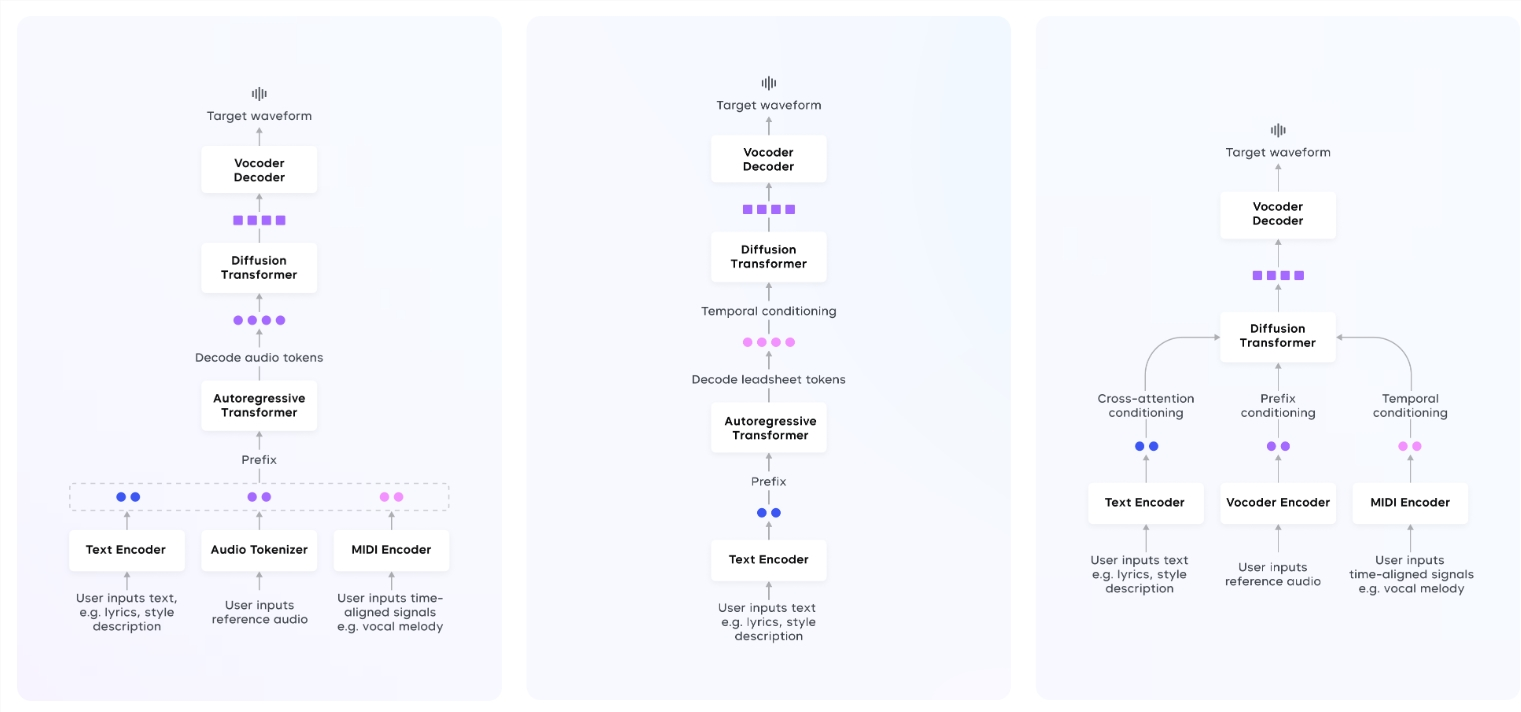
表示学习模块将原始音频信号压缩成三种中间表示,适用于不同的音乐生成和编辑任务。生成模块则通过自回归模型和扩散模型,将用户的输入转化为音乐表示。而最后的渲染模块则负责将这些中间表示变成你耳朵可享受的高质量音频。
为了保证音乐的质量,Seed-Music 采用了多种技术:自回归语言模型逐步生成音频符号,扩散模型则通过去噪手段让音乐更加清晰,而声码器则将这些音乐 “代码” 翻译成可播放的高保真声音。
Seed-Music 的训练过程也很有趣,分为预训练、微调和后训练三个阶段。通过大规模的音乐数据,模型获得基础能力,再通过微调提升具体任务的表现,最后还会通过强化学习不断优化生成结果。
项目地址:https://team.doubao.com/en/special/seed-music
本文来源于#站长之家,由@tom 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/1863.html



的语音识别模型")

















