8月26日消息:摩尔线程智能科技有限公司(Moore Threads)近日宣布,其基于国产全功能GPU训练和推理的大型语音模型MooER(摩耳)已成功开源。这一举措标志着国产GPU在人工智能领域的应用实力,同时为全球音频AI技术的发展注入了新的活力。

MooER模型采用了创新的三部分结构设计,包括Encoder(编码器)、Adapter(适配器)和Decoder(大型语言模型,LLM)。这种设计使得MooER能够有效地处理原始音频数据,提取关键特征,并执行包括语音识别和翻译在内的下游任务。
在与多个知名开源音频理解大模型的对比测试中,MooER展现出了卓越的性能。在中文测试集上,MooER的字错误率(CER)达到了4.21%,在英文测试集上的词错误率(WER)为17.98%,与其他顶级模型相比表现更优或相当。特别值得一提的是,在Covost2zh2en中译英测试集上,MooER的BLEU分数高达25.2,大幅领先其他开源模型,达到了工业级应用的水平。
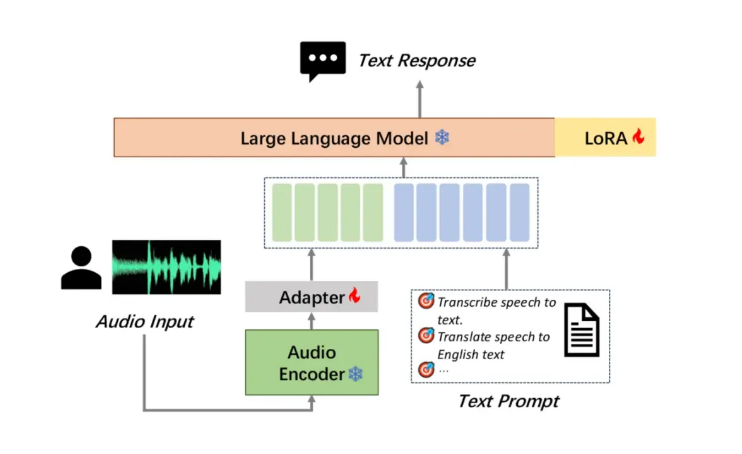
摩尔线程的项目团队已经开源了推理代码和基于5000小时数据训练的模型,并计划进一步开源训练代码和基于8万小时数据训练的增强版模型。基于8万小时数据训练的MooER-80K模型在性能上更进一步,在中文测试集上的CER降至3.50%,英文测试集上的WER优化到12.66%,显示了其巨大的发展潜力。
摩尔线程开源MooER的行动不仅展示了国产GPU的强大计算能力,也为音频AI技术的创新应用和普及提供了新的可能性。随着更多训练数据和代码的开源,业界期待MooER能在语音识别、翻译等领域带来更多突破性进展。
有关MooER的更多信息和开源资源,可以通过以下链接访问:
GitHub:MooreThreads/MooER
ModelScope:MooreThreadsSpeech/MooER-MTL-5K
Huggingface:mtspeech/MooER-MTL-5K
本文来源于#网络,由@tom 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/1734.html





















