Meta最新发布了Audiobox,这是一款基于语音和自然语言提示生成音频的先进研究模型。通过结合语音输入和文本提示,Audiobox可以轻松生成各种声音,包括语音、音效和音景,从而为多种用例提供定制音频。
Audiobox是Voicebox的继任者,进一步推动了音频生成领域的发展。与Voicebox相比,Audiobox具有更强大的可控性,用户可以使用文本描述提示来指定语音和音效的风格,这是Voicebox不支持的功能。通过同时使用语音输入和文本提示,用户可以实现自由形式的语音重塑,这在当前的模型中尚属首次。
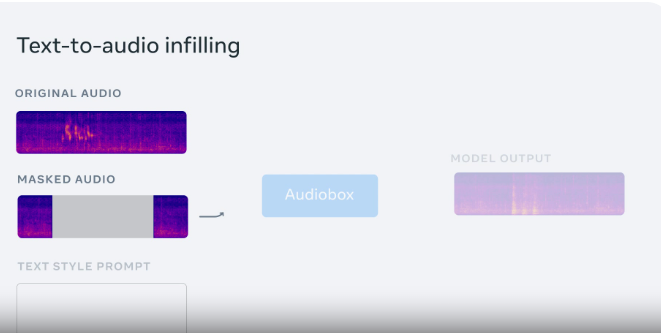
这款模型的独特之处在于,它允许用户使用自然语言提示描述他们想要生成的声音或语音类型。例如,如果有人想要生成一片音景,他们可以给模型一个文本提示,如“一条奔流的河流和鸟儿的鸣叫”。
Audiobox不仅在语音生成方面表现出色,还在音效生成方面表现出色。经过内部测试,Audiobox在质量和相关性方面明显超过先前的最佳模型,并在主观评估中以超过30%的样式相似性优势击败了Voicebox。
为了促进领域的发展并确保研究的负责任性,Meta计划邀请研究人员和学术机构申请资金,用于Audiobox的安全和责任研究。这一举措反映了他们对AI创新的关切,强调了与研究社区合作的重要性。
Audiobox的推出标志着音频生成领域的一项重要进展,Meta希望通过这一创新降低音频创作的门槛,使任何人都能轻松成为音频内容创作者。这对于视频、播客、游戏等多种用例都具有潜在的影响,为未来的音频创作开辟了新的可能性。
本文来源于#站长之家,由@tom 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/161.html
实战:Web版背单词应用开发演示")




















