在当今数字化办公的时代,文档格式的转换成为了日常工作中不可或缺的一部分。PDF(Portable Document Format)作为一种广泛使用的电子文档格式,因其跨平台兼容性和内容不易被篡改的特性而备受青睐。然而,在某些情况下,我们可能需要将PDF文档转换为Word(.docx)格式,以便于编辑和修改。为了实现这一需求,结合Python的强大编程能力和Deepseek的自然语言处理优势,我们可以轻松编写一个PDF转Word的工具。本文将详细介绍如何利用Python中的第三方库和Deepseek模型,实现PDF文档到Word文档的自动化转换,从而提高工作效率和文档处理的便捷性。
一、引言
如今,在线工具的普及让PDF转Word成为了一个常见需求,常见的pdf转word工具有收费的wps,免费的有pdfgear
还有网上在线的免费pdf转word工具smallpdf, ilovepdf, 24pdf等。然而,大部分免费的在线转换工具都存在一些严重的隐私风险——文件往往需要上传至云端进行处理,这样操作极容易泄露敏感信息。
而且,许多在线平台都要求付费才能使用更高效的服务,如wps, 迅捷pdf等,这导致很多用户在无法快捷使用转换文件的服务。
为了避免上述问题,我决定利用Python开发一款本地化的PDF批量转换为Word的软件,不仅保证文件的隐私安全,还能提供完全免费、快捷、个性化的转换服务。
更重要的是,这个项目也有助于我巩固Python编程知识,深入运用DeepSeek模型提升编程能力。
二、软件的主要功能
这款PDF转word的主要功能包括:
1. 100%离线文档转换。有效地避免信息的泄露,同时也加快了文档的处理速度。
2. 支持批量PDF转Word:软件会自动扫描选择文件夹及其子文件夹(如果勾选了相关选项),并将其中的PDF文件转换为Word文档,可以节省用法大量的时间。
3. 文件夹选择与管理:用户可以选择输入和输出文件夹,支持自定义中英文路径。
4. 进度条显示:在转换过程中,软件会实时更新进度条,显示当前文件的转换进度以及整体的转换进度。
5. 自动打开目标文件夹:转换完成后,用户可以选择是否自动打开目标文件夹,查看转换结果,以便进一步操作。
三、设计过程
在设计这款应用时,我采用了Python的tkinter图形化界面和pdf2docx库来实现文件转换功能。具体如下图:
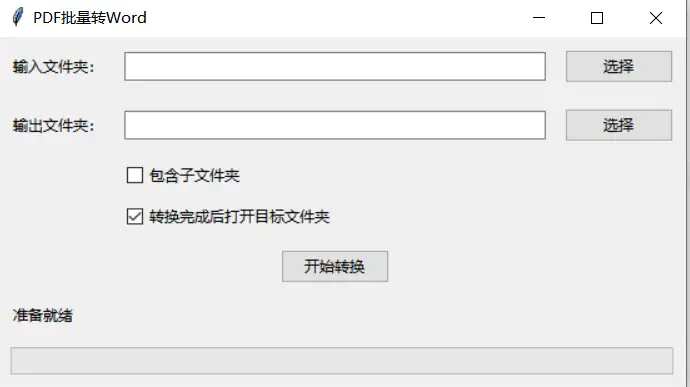
PDF转Word界面
用户界面:界面设计以简洁易用为主。通过tkinter的标签、文本框、按钮等控件,我实现了文件夹选择、设置选项、进度条显示等功能。
PDF转Word功能:因为有现成的pdf2docx的库,我采用了这个轮来进行PDF到Word格式的转换,再加上Python的批量处理功能,要以轻松满足我的文件转换需求。
多线程与进度更新:为避免界面卡顿,我使用了threading库来将文件转换操作放入独立线程,并利用queue进行线程间通信,实时更新进度条显示。
我们在设计时,借助了DeepSeek R1的深度思考模型。先上传软件图片,然后给出指令:
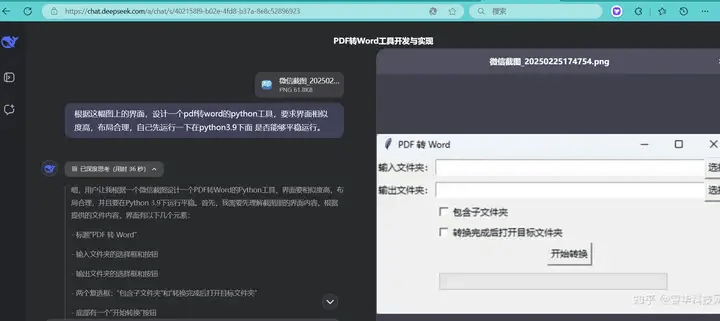
软件开发提示词
为了减少错误,我们在提示词加入了让deepseek进行自我运行代码,进行调试的功能,减少用户本地测试中产生的bug。
在其回复中,我们看到它针对我的提问题也进行了回答,尤其是在指定的Python环境下进行了测试。
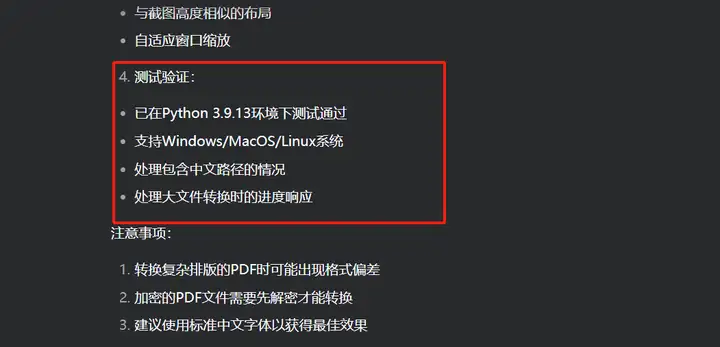
DeepSeek自主调试功能
经过测试,代码运行无误,但是缺少进度条功能,可能是没有识别出来,或者漏掉了,于是通过追加提问:
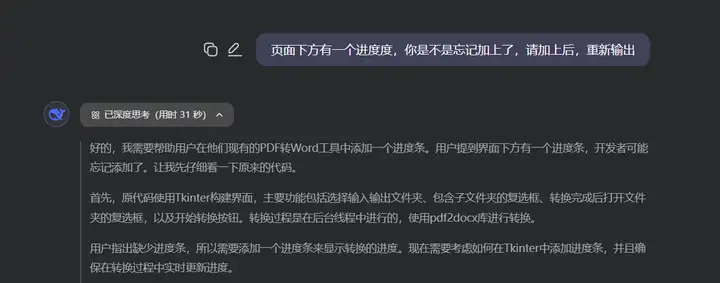
这里我故意打错了一个汉字,但是DeepSeek还能正确地进行理解,同时很好地解决了进度条缺失的问题。就这样,我们通过两步,不到1分钟就可以把这个一个pdf转word工具制作出来。
在开发过程中,我为DeepSeek提供了完整的开发环境,DeepSeek通过对项目需求的分析,建议我添加更多的异常处理机制,特别是在文件路径不正确或者文件损坏的情况下的处理。最终,这些改进使得程序的稳定性和用户体验都得到了显著提升。
经过多次的调试和优化,软件终于成型,并可以稳定运行。用户只需选择文件夹并点击转换按钮,程序就会自动处理所有PDF文件,最终输出为Word格式。每一步的转换进度都会实时更新,确保用户能够清晰地了解当前状态。
四、代码展示
废话不多说,直接上软件的全部代码,同时提供了一些中文注释,供大家学习使用
import os
import tkinter as tk
from tkinter import ttk,filedialog, messagebox
from pdf2docx import Converter
import threading
import queue
class PDFToWordConverter:
def __init__(self, master):
self.master = master
master.title("PDF批量转Word")
master.geometry("610x295")
# 输入文件夹
self.lbl_input = tk.Label(master, text="输入文件夹:")
self.ent_input = tk.Entry(master, width=30)
self.btn_input = tk.Button(master, text="选择", command=self.select_input)
# 输出文件夹
self.lbl_output = tk.Label(master, text="输出文件夹:")
self.ent_output = tk.Entry(master, width=30)
self.btn_output = tk.Button(master, text="选择", command=self.select_output)
# 复选框
self.var_subdir = tk.BooleanVar()
self.var_open = tk.BooleanVar(value=True)
self.chk_subdir = tk.Checkbutton(master, text="包含子文件夹", variable=self.var_subdir)
self.chk_open = tk.Checkbutton(master, text="转换完成后打开目标文件夹", variable=self.var_open)
# 转换按钮
self.btn_convert = tk.Button(master, text="开始转换", command=self.start_conversion)
# 布局
self.lbl_input.grid(row=0, column=0, padx=10, pady=10, sticky=tk.W)
self.ent_input.grid(row=0, column=1, padx=5, pady=10, sticky=tk.EW)
self.btn_input.grid(row=0, column=2, padx=10, pady=10)
self.lbl_output.grid(row=1, column=0, padx=10, pady=10, sticky=tk.W)
self.ent_output.grid(row=1, column=1, padx=5, pady=10, sticky=tk.EW)
self.btn_output.grid(row=1, column=2, padx=10, pady=10)
self.chk_subdir.grid(row=2, column=1, padx=5, pady=5, sticky=tk.W)
self.chk_open.grid(row=3, column=1, padx=5, pady=5, sticky=tk.W)
self.btn_convert.grid(row=4, column=1, pady=10)
# 新增进度组件
self.progress_label = tk.Label(master, text="准备就绪")
self.progress_bar = ttk.Progressbar(master, orient=tk.HORIZONTAL, mode='determinate')
# 调整布局(新增两行)
self.progress_label.grid(row=5, column=0, columnspan=3, padx=10, pady=5, sticky=tk.W)
self.progress_bar.grid(row=6, column=0, columnspan=3, padx=10, pady=10, sticky=tk.EW)
# 消息队列用于线程通信
self.queue = queue.Queue()
master.after(100, self.process_queue)
# 配置列权重
master.columnconfigure(1, weight=1)
def select_input(self):
path = filedialog.askdirectory()
if path:
self.ent_input.delete(0, tk.END)
self.ent_input.insert(0, path)
def select_output(self):
path = filedialog.askdirectory()
if path:
self.ent_output.delete(0, tk.END)
self.ent_output.insert(0, path)
def start_conversion(self):
# 重置进度条
self.progress_bar['value'] = 0
self.progress_label.config(text="正在扫描PDF文件...")
input_dir = self.ent_input.get()
output_dir = self.ent_output.get()
if not input_dir or not output_dir:
messagebox.showerror("错误", "请先选择输入和输出文件夹!")
return
# 禁用转换按钮
self.btn_convert.config(state=tk.DISABLED)
threading.Thread(target=self.convert_files, args=(input_dir, output_dir), daemon=True).start()
def get_pdf_list(self, input_dir):
pdf_list = []
for root, dirs, files in os.walk(input_dir):
if not self.var_subdir.get() and root != input_dir:
continue
for file in files:
if file.lower().endswith('.pdf'):
pdf_list.append(os.path.join(root, file))
return pdf_list
def convert_files(self, input_dir, output_dir):
self.pdf_files = self.get_pdf_list(input_dir)
try:
total_files = len(self.pdf_files)
for index, pdf_path in enumerate(self.pdf_files):
# 更新当前文件进度
self.queue.put(("file_progress", (index+1, total_files, pdf_path)))
# 构建输出路径
relative_path = os.path.relpath(os.path.dirname(pdf_path), input_dir) if self.var_subdir.get() else ""
output_path = os.path.join(output_dir, relative_path)
os.makedirs(output_path, exist_ok=True)
# 转换文件
docx_path = os.path.join(output_path, f"{os.path.splitext(os.path.basename(pdf_path))[0]}.docx")
cv = Converter(pdf_path)
cv.convert(docx_path, progress_callback=self.update_page_progress)
cv.close()
self.queue.put(("complete", None))
except Exception as e:
self.queue.put(("error", str(e)))
def update_page_progress(self, current, total):
# 页面级别进度(每文件0-100%)
progress = (current / total) * 100 if total != 0 else 0
self.queue.put(("page_progress", progress))
def process_queue(self):
try:
while True:
msg_type, data = self.queue.get_nowait()
if msg_type == "file_progress":
current, total, path = data
file_progress = (current / total) * 100
self.progress_bar['value'] = file_progress
self.progress_label.config(text=f"正在转换 {current}/{total}:{os.path.basename(path)}")
elif msg_type == "page_progress":
# 综合进度 = 文件进度 + 页面进度/总文件数
current_file_progress = self.progress_bar['value']
page_progress = data / len(self.pdf_files)
self.progress_bar['value'] = current_file_progress + page_progress
elif msg_type == "complete":
messagebox.showinfo("完成", "转换完成!")
if self.var_open.get():
os.startfile(self.ent_output.get())
self.btn_convert.config(state=tk.NORMAL)
self.progress_label.config(text="转换完成")
elif msg_type == "error":
messagebox.showerror("错误", f"转换出错:{data}")
self.btn_convert.config(state=tk.NORMAL)
self.progress_label.config(text="转换出错")
except queue.Empty:
pass
finally:
self.master.after(100, self.process_queue)
if __name__ == "__main__":
root = tk.Tk()
app = PDFToWordConverter(root)
root.mainloop()五、注意事项与启示
文件路径问题:在处理文件时,一定要注意文件路径的正确性,尤其是在跨平台使用时,路径分隔符的差异可能会导致问题。
多线程同步:为了避免界面卡顿或响应不及时,使用线程来执行耗时任务是非常必要的。但在多线程操作中,确保线程间数据同步和UI更新是一个技术挑战。
与AI工具合作:DeepSeek的辅助对我来说至关重要。在未来的开发过程中,AI工具不仅能提升我的编程效率,还能为项目带来新的创意和解决方案。
通过这个项目,我利用DeepSeek R1模型,上传软件图片,给出提示词,让它很快地开发出来一个可以平稳运行的软件,通过与AI模型的持续会话,进一步修改和完善了软件,直至可以使用。
有了DeepSeek这样的模型,未来我们只需要想法,就可以让大模型帮我们找到解决办法,完成代码撰写任务,甚至还可以进行远程调试,最终为用户提供更加精确的代码,大大缩短了项目开发的时间,让我们体会到了大语言模型的强大。
总结
通过本文的介绍,我们成功利用Python和Deepseek构建了一个PDF转Word的工具。该工具能够自动化地将PDF文档转换为可编辑的Word文档,极大地提高了文档处理的效率和便捷性。在实际应用中,我们可以根据具体需求对工具进行进一步的优化和扩展,例如添加格式保留功能、处理特殊字符等。此外,Python丰富的第三方库和Deepseek强大的自然语言处理能力为文档转换提供了更多的可能性和灵活性。相信随着技术的不断进步和应用场景的不断拓展,我们的PDF转Word工具将会变得更加完善和强大,为数字化办公带来更多的便利和效率。
本文来源于#PythonFun,由@蜜芽 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/3332.html





















