在当今信息爆炸的时代,高效地管理和利用知识成为了个人和企业竞争力的关键。DeepSeek与RAGFlow作为两款强大的工具,为构建个性化知识库提供了前所未有的便利。然而,在线版本的服务往往受限于数据隐私、性能瓶颈及定制化需求等诸多因素。因此,本地部署DeepSeek与RAGFlow成为了越来越多用户的首选。本指南将带您一步步走进本地部署的世界,从环境准备到实战操作,全面解析如何在本地环境中轻松搭建起属于自己的个性化知识库,让知识的力量触手可及。
一、理论基础
1.为何不直接使用在线版deepseek
1.1 数据隐私与安全
在线版DeepSeek需要将数据传输到云端服务器处理,存在日志留存的可能,用户需要信任服务商的隐私政策。对于涉及敏感数据的场景,如金融、医疗等行业,数据隐私和合规性要求极高,在线版可能无法满足这些需求。
1.2 性能与稳定性
在线版依赖网络和服务器资源,响应速度可能受网络带宽和服务器负载影响,尤其在处理复杂任务或高峰期时,可能出现延迟或性能瓶颈。相比之下,本地部署可以最大化利用本地硬件资源,性能更稳定,适合高负载或大规模数据处理。
1.3 功能与定制化
在线版的功能相对固定,无法修改模型参数或进行定制化优化。如果用户需要针对特定行业或任务进行模型微调,在线版可能无法满足这些需求。
1.4 成本与长期使用
在线版通常采用按需付费模式,初期成本较低,但长期大规模使用时,费用可能显著增加。相比之下,本地部署虽然初期投入较高,但长期使用成本可控。
1.5 使用场景与需求
在线版适合快速体验、临时性需求或轻量级任务,但对于需要7×24小时高频调用、私有化知识库构建或处理敏感数据的场景,在线版可能不是最佳选择。
2.本地如何实现
2.1 本地部署DeepSeek 2.2 个性化知识库构建
使用RAG技术(Retrieval-Augmented Generation,检索增强生成)构建个人知识库。本地部署RAG技术所需要的自带Embedding模型的开源框架RAGFlow。
3.RAG技术原理
检索(Retrieval):当用户提出问题时,系统会从外部知识库中检索出与用户输入相关的内容。
增强(Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。这让生成模型Deepseek可以利用外部知识,使生成的答案更准确和丰富。
生成(Generation):生成模型基于增强后的输入生成最终的回答。它结合用户输入和检索到的信息,生成符合逻辑、准确且可读的文本内容。
4.为什么要用Embedding
Embedding 是一种将离散变量转化为连续向量的技术,广泛应用于自然语言处理(NLP)、推荐系统等领域。通过Embedding,可以将文本中的词语、句子甚至是文档映射到一个高维的向量空间中,使得语义相似的词或文本在这个空间中距离较近。这种表示方式不仅能够保留原始数据的语义信息,还可以作为许多机器学习模型的输入特征。它有如下特点:
语义理解:Embedding能够捕捉词汇间的语义关系,这对于需要深层次语义理解的任务(如问答系统、搜索引擎等)非常重要。DeepSeek和RAGFlow虽然各自有其优势,但它们可能无法直接提供这种基于向量的语义表示。
灵活 性与可扩展性:拥有自己的Embedding模型意味着你可以针对特定的应用场景或领域定制化训练模型,从而更好地适应特定需求。这为解决方案提供了更大的灵活性和可扩展性。
性能优化:在某些情况下,使用预训练的Embedding模型并在此基础上进行微调,可能会比从头开始训练整个系统(例如DeepSeek或RAGFlow)更有效率,尤其是在资源有限的情况下。
组合使用:Embedding模型可以作为其他复杂模型(包括DeepSeek、RAGFlow等)的一个组件来使用。比如,在检索增强生成(RAG)架构中,通常首先利用Embedding模型对查询和文档进行编码,然后根据这些编码后的向量来进行匹配和排序。
二、安装CUDA,显卡也能参与运算
在cmd窗口运行nvidia-smi查看CUDA版本号,然后下载相同版本的cuda toolkit就可以了,只能低于不能高于这个版本。解决ollama不在GPU上跑的问题。
下载CUDA:CUDA Toolkit Archive | NVIDIA Developer
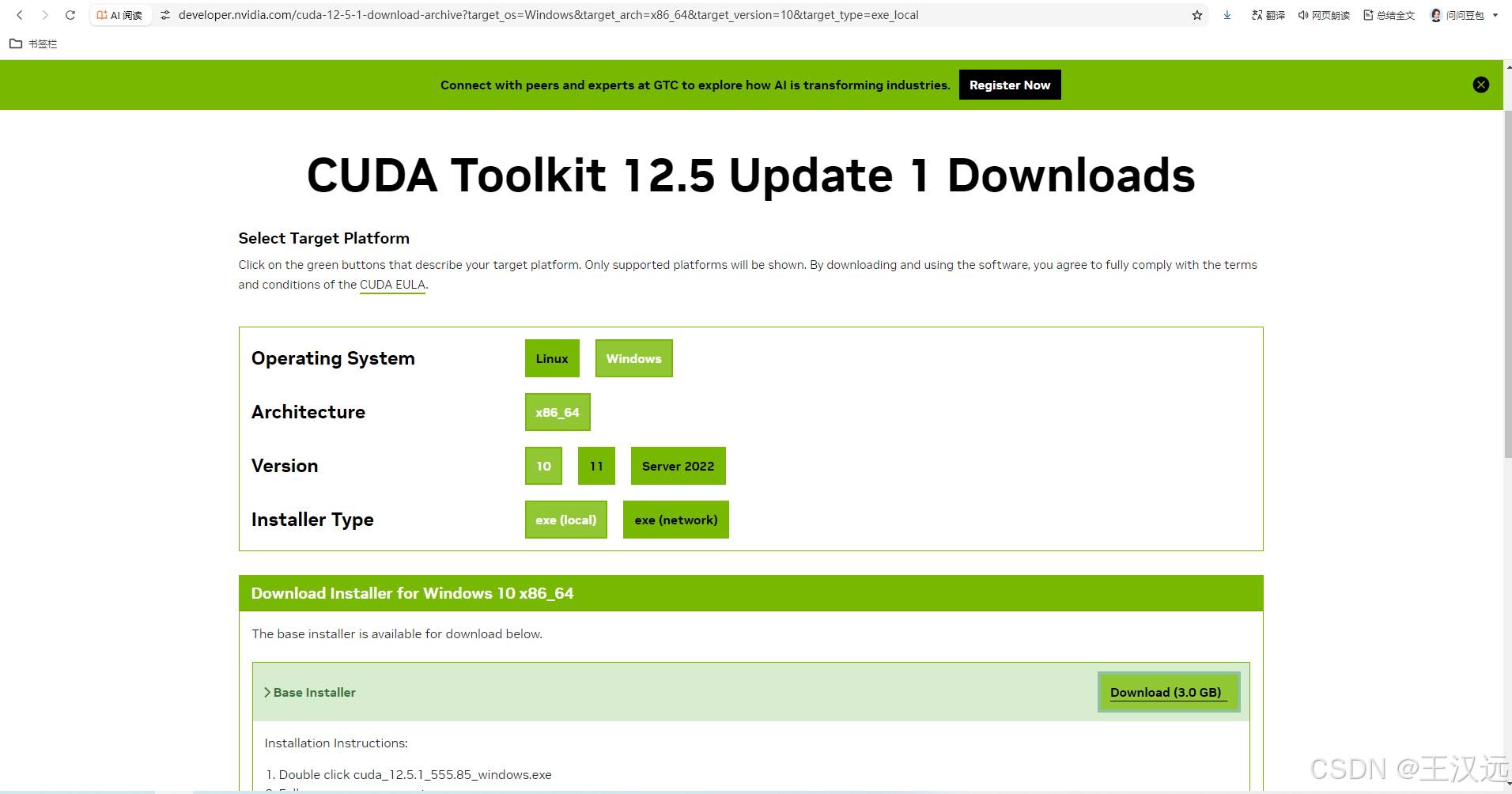
nvcc --version检测安装了CUDA。
三、安装Ollama,用它来运行大模型
Ollama是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)
而设计。
下载Ollama
环境变量设置:
变量名OLLAMA_HOST 变量值 0.0.0.0
变量名OLLAMA_MODELS,变量值E:\backup\software\ds\ollama
变量名OLLAMA_ORIGINS,变量值*
四、运行deepseek
ollama run deepseek-r1:1.5b
五、安装配置docker
下载docker:Docker: Accelerated Container Application Development
我的windows没配置成功,只好用centos虚拟机的docker。
下一步要安装的RAGFlow占用虚拟机磁盘空间390G,加上内存也会占用20多个G的空间(分配的内存是多少占用多少磁盘空间),所以最好预留至少450G的磁盘空间给虚拟机。可以用fdisk /dev/sda去操作增加空间。
在fdisk交互界面中,按以下步骤操作:
输入 n 创建新分区。
根据提示选择主分区或扩展分区(通常选择主分区)。
选择分区号(如3,因为已经有sda1和sda2)。
按回车键接受默认的第一个扇区位置。
按回车键接受最后一个扇区位置。
输入 w 保存更改并退出。
为了使内核重新读取分区表,运行以下命令:
sudo partprobe /dev/sda
假设新分区为sda3,现在需要将它添加到卷组中(假设卷组名为centos):
sudo pvcreate /dev/sda3 sudo vgextend centos /dev/sda3
接下来,扩展逻辑卷centos-root以及相应的文件系统:
sudo lvextend -l +100%FREE /dev/mapper/centos-root sudo xfs_growfs /
通过以上步骤,你应该能够将未分配的磁盘空间加入到根目录/所在的逻辑卷,并扩展文件系统以使用新增加的空间。
关防火墙:
sudo systemctl stop firewalld && sudo systemctl disable firewalld
查看防火墙状态:
sudo systemctl status firewalld
更新到最新版,安装步骤如下:
1. 更新系统包
在安装 Docker 之前,要先更新centos7.x,需要修改/etc/yum.repos.d/CentOS-Base.repo:
cd /etc/yum.repos.d mv CentOS-Base.repo CentOS-Base.repo.bak vi CentOS-Base.repo
[base] name=CentOS-$releasever - Base baseurl=http://vault.centos.org/7.9.2009/os/$basearch/ gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7 [updates] name=CentOS-$releasever - Updates baseurl=http://vault.centos.org/7.9.2009/updates/$basearch/ gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7 [extras] name=CentOS-$releasever - Extras baseurl=http://vault.centos.org/7.9.2009/extras/$basearch/ gpgcheck=1 gpgkey=file:///etc/p/rkipm-gpg/RPM-GPG-KEY-CentOS-7
yum clean all yum makecache sudo yum update -y
2. 安装必要的依赖包
安装一些必要的工具和依赖包,例如 yum-utils,它可以帮助我们管理软件仓库。
sudo yum install -y yum-utils
3. 添加 Docker 的官方软件仓库
Docker 提供了官方的软件仓库,通过它来安装 Docker 可以确保版本的稳定性和安全性。运行以下命令添加 Docker 的官方仓库:
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
4. 安装 Docker
安装 Docker 社区版(Docker CE):
sudo yum install -y docker-ce docker-ce-cli containerd.io
如果需要安装特定版本的 Docker,可以先运行以下命令查看可用版本:
bash复制
yum list docker-ce --showduplicates | sort -r
然后选择一个版本进行安装,: 例如 ```bash sudo yum install docker-ce-<版本号>
5. 启动 Docker 服务
安装完成后,需要启动 Docker 服务并设置开机自启:
sudo systemctl start docker sudo systemctl enable docker
6. 验证 Docker 是否安装成功
运行以下命令来验证 Docker 是否安装成功:
sudo docker run hello-world
如果安装成功,你会看到一条欢迎信息,说明 Docker 已经正常运行。
7. (可选)将当前用户添加到 Docker 组默认
一般情况下,Docker 命令需要管理员权限(sudo)。为了避免每次都输入 sudo,可以将当前用户添加到 docker 用户组:
sudo usermod -aG docker $USER
之后需要重新登录或重启系统,使用户组生效。
8. 配置 Docker 镜像加速
需要新增或修改sudo vi /etc/docker/daemon.json:
{
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker-0.unsee.tech"
]
}sudo systemctl daemon-reload sudo systemctl restart docker
9. 安装 Docker Compose
如果需要使用 Docker Compose 来管理多容器应用,可以通过以下命令安装:
sudo curl -L "https://github.com/docker/compose/releases/download/$(curl -s https://api.github.com/repos/docker/compose/releases/latest | grep -Po '"tag_name": "\K.*\d')" /docker-compose-linux-x86_64" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose
10. 验证安装
验证 Docker 是否正确安装并且服务已正常启动:
sudo docker --version sudo docker run hello-world
后者将会下载一个测试镜像并在容器中运行它,如果一切正常,你会看到一条欢迎信息,说明 Docker 已成功安装并能正常工作。
六、RAGFlow
1. 下载RAGFlow
2.确保 vm.max_map_count 不小于 262144
如需确认 vm.max_map_count 的大小:
sysctl vm.max_map_count
如果 vm.max_map_count 的值小于 262144,可以进行重置,这里我们设为 262144:
sudo sysctl -w vm.max_map_count=262144
你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
vm.max_map_count=262144
3.切换到ragflow目录,执行
docker compose -f docker/docker-compose.yml up -d
以下命令是解决装坏了才要做的,正常不要做:
docker stop $(docker ps -q) # 停止所有正在运行的容器
docker rm $(docker ps -a -q) # 删除所有容器
docker rmi $(docker images -q) # 删除所有镜像
docker volume rm $(docker volume ls -q) # 删除所有卷
docker network prune # 清理未使用的网络
以下命令是切换到ragflow/docker目录,可以重新启动ragflow:
docker compose stop docker compose up -d
4.服务器启动成功后再次确认服务器状态
docker logs -f ragflow-server
出现以下界面提示说明服务器启动成功:
____ ___ ______ ______ __ / __ \ / | / ____// ____// /____ _ __ / /_/ // /| | / / __ / /_ / // __ \| | /| / / / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ / /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/ * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:9380 * Running on http://x.x.x.x:9380 INFO:werkzeug:Press CTRL+C to quit
如果您跳过这一步系统确认步骤就登录 RAGFlow,你的浏览器有可能会提示 network anormal 或 网络异常,因为 RAGFlow 可能并未完全启动成功。
在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
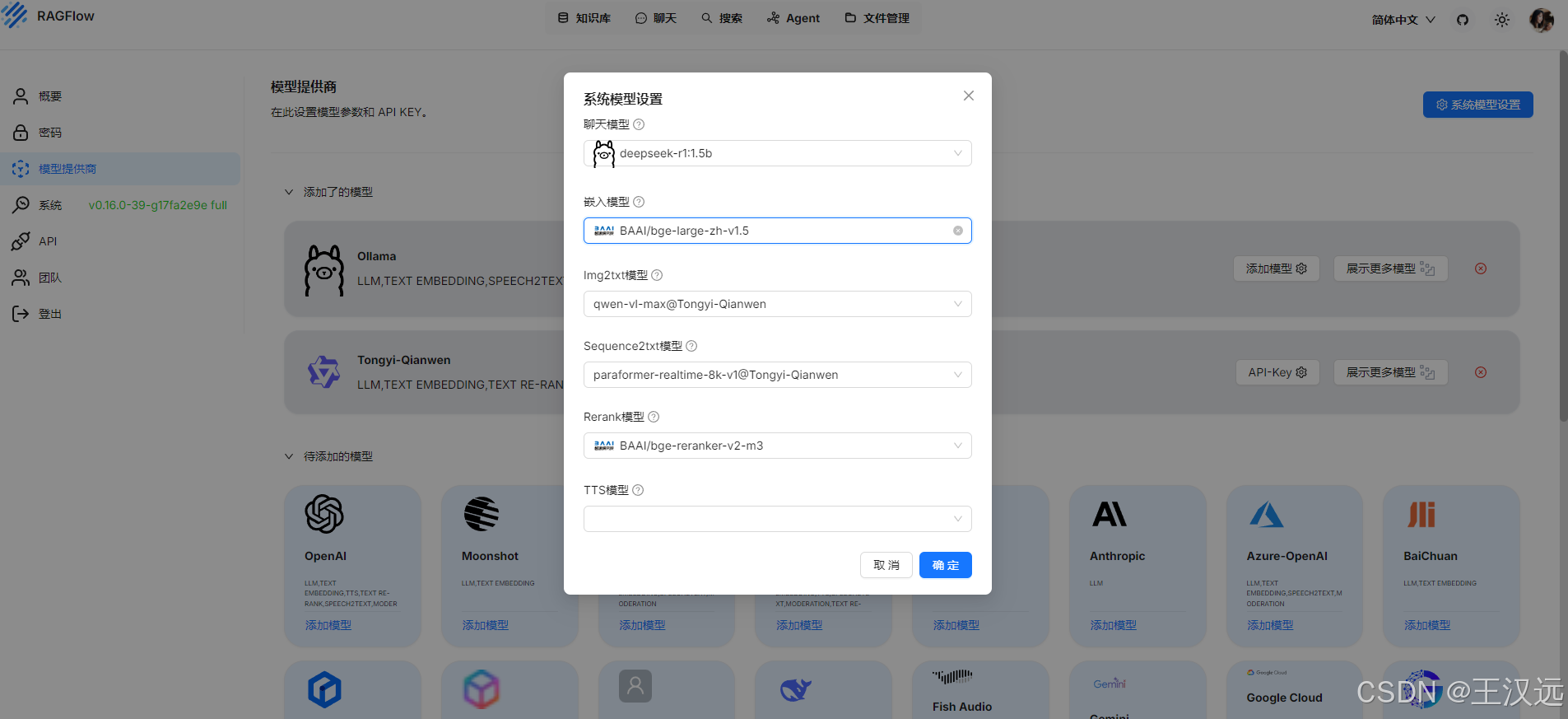
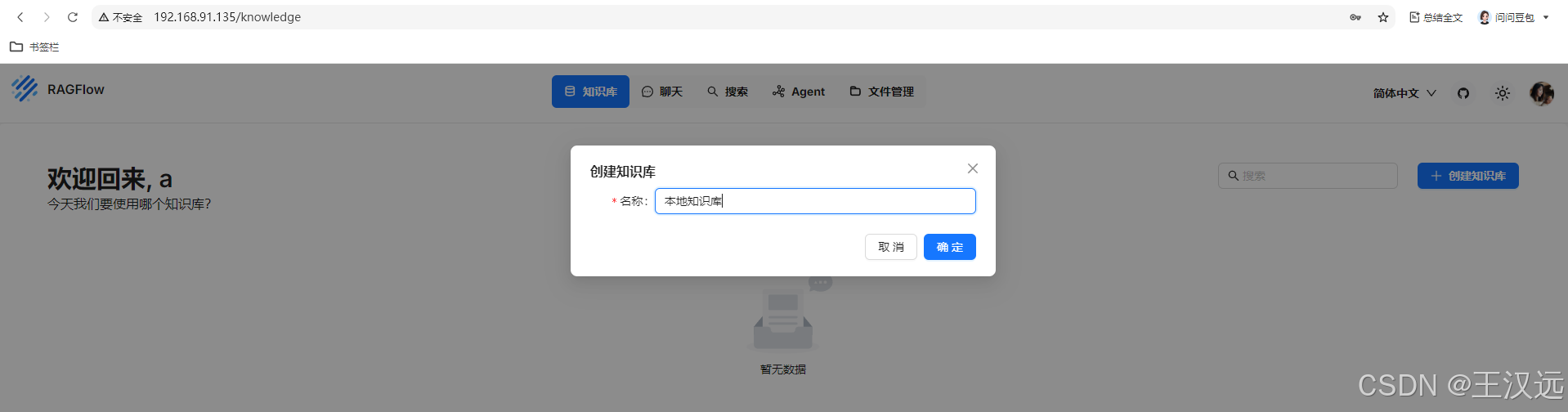
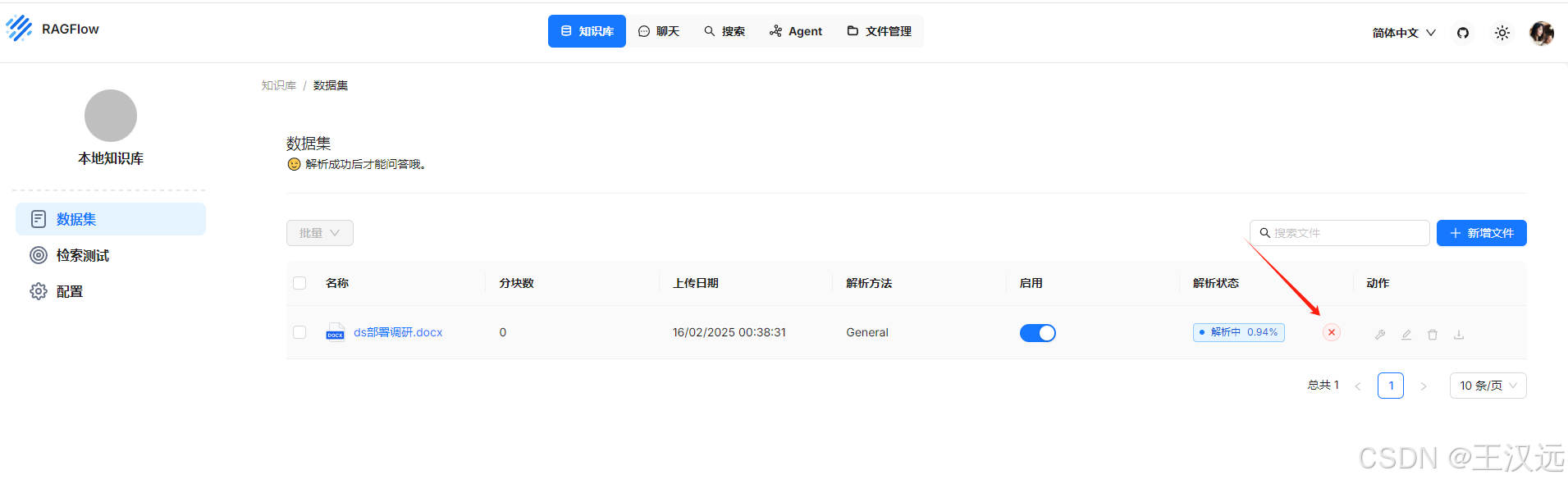
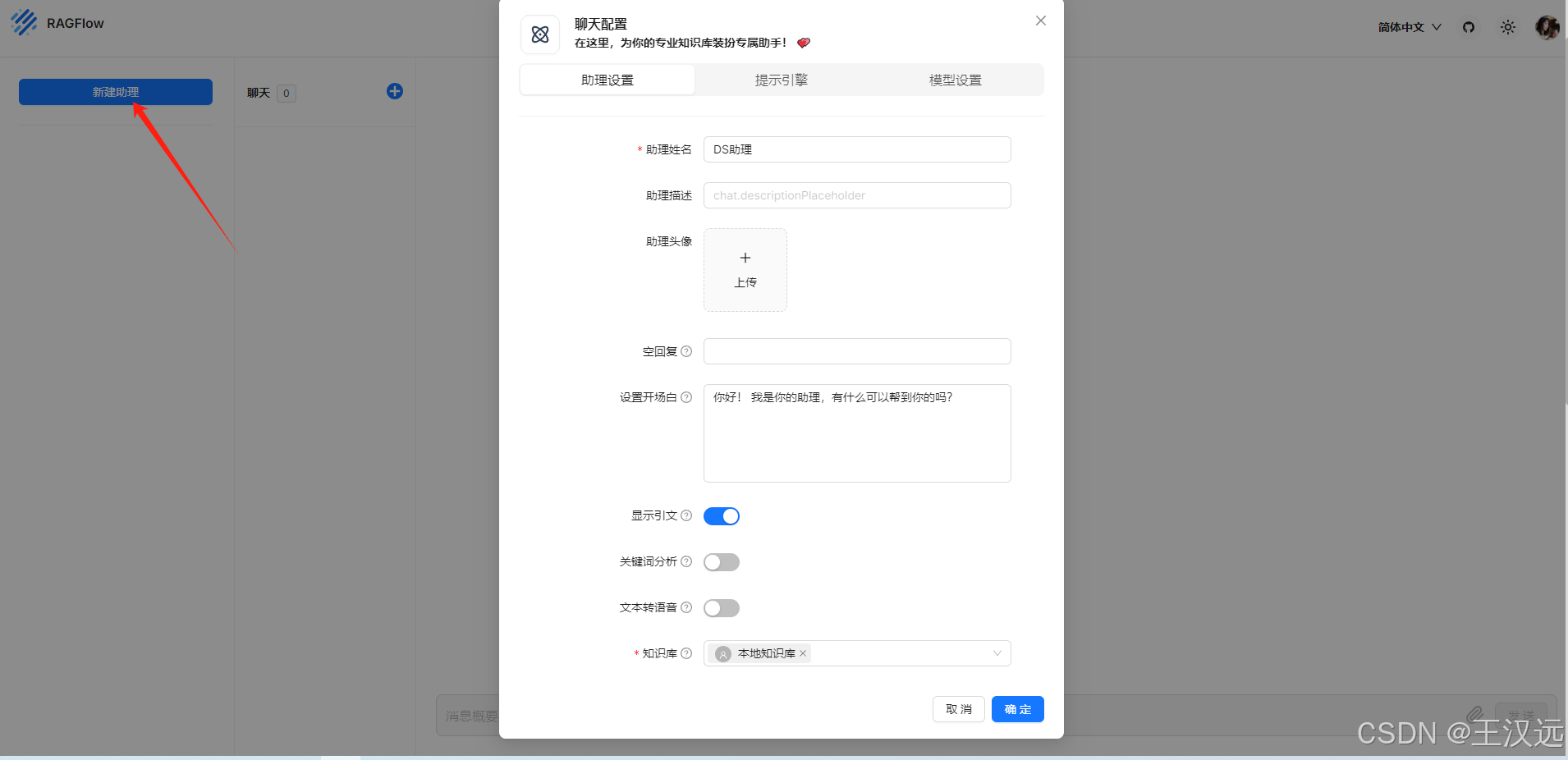
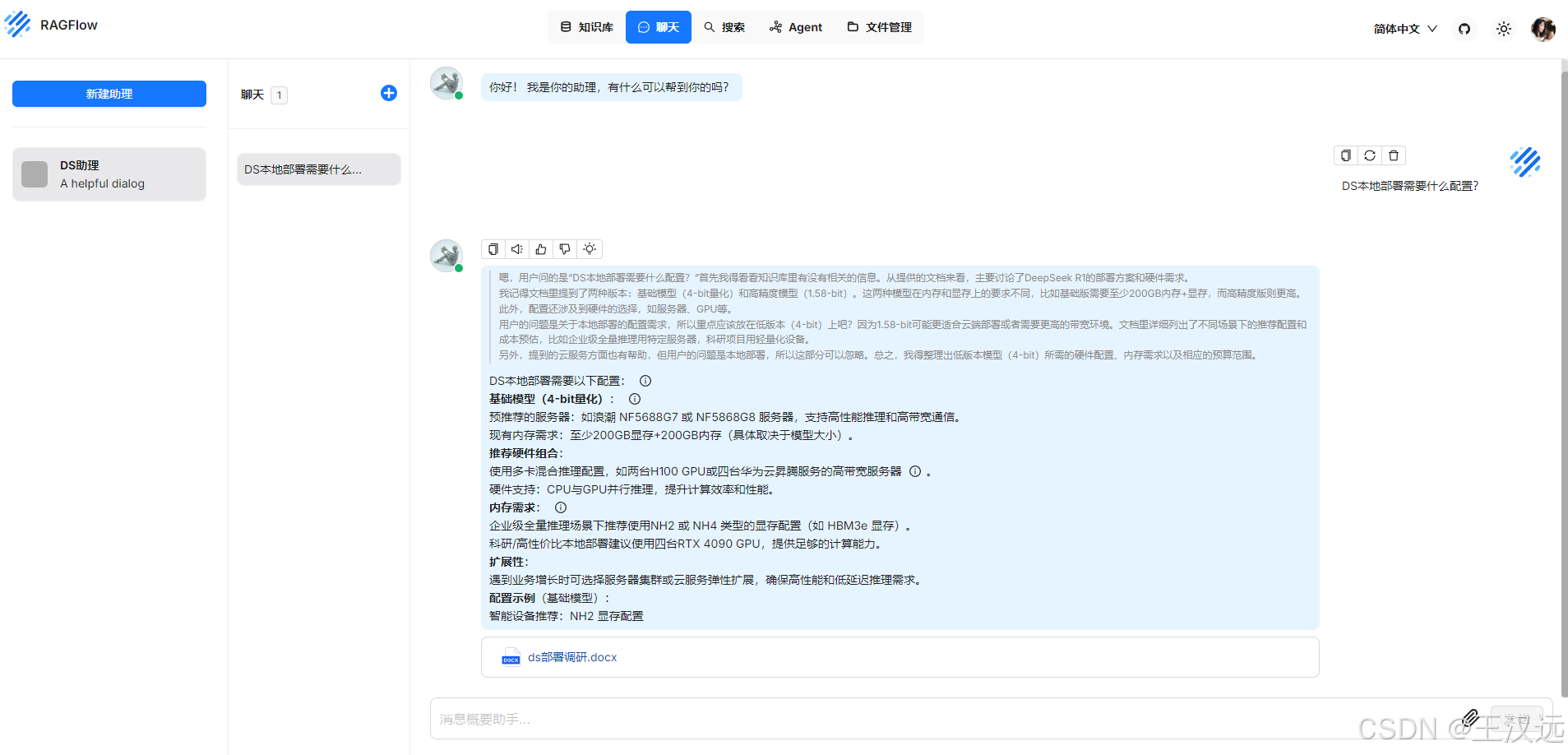
5.新建知识库


总结
通过本指南的详细介绍,我们深入了解了DeepSeek与RAGFlow本地部署的全过程。从对在线版局限性的分析,到本地部署的必备条件与步骤,再到Docker环境的搭建与RAGFlow的配置,每一个细节都旨在为用户提供一个清晰、完整的实践路径。本地部署不仅解决了数据隐私与安全问题,更在性能与稳定性、功能定制化等方面为用户带来了显著的提升。随着个性化知识库的建立,用户将能够更高效地管理和利用知识资源,为个人的学习与工作注入源源不断的动力。希望本指南能够成为您构建个性化知识库的得力助手,让知识的力量在您的指尖绽放。
本文来源于#王汉远,由@蜜芽 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/3249.html
")



")
















