在数字化时代,PDF文件已成为我们日常工作和生活中不可或缺的一部分。无论是合同、报告还是电子书,PDF都以其便携性和跨平台性赢得了广泛的认可。然而,在处理大量PDF文件时,我们有时会遇到需要拆分文件的情况,比如提取其中的某些页面进行单独保存或分享。这时,一款高效、易用的PDF拆分工具就显得尤为重要。本文将介绍一款基于Python编写的脚本,它能够帮助你轻松实现PDF文件的拆分操作。这款脚本不仅功能强大,而且操作简便,即使是没有编程基础的用户也能快速上手。通过本文的学习,你将掌握如何使用这款脚本高效地拆分PDF文件,让你的工作更加得心应手。
一、简介
PyMuPDF,简称fitz,是一个轻量级的Python库,它基于MuPDF的C++库,提供了丰富的功能,包括但不限于PDF的读取、编辑、转换和渲染。Fitz作为PyMuPDF的子模块,简化和封装了PyMuPDF的功能,使得在Python中处理PDF文件更加简单。
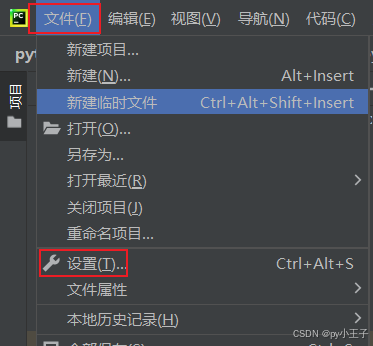
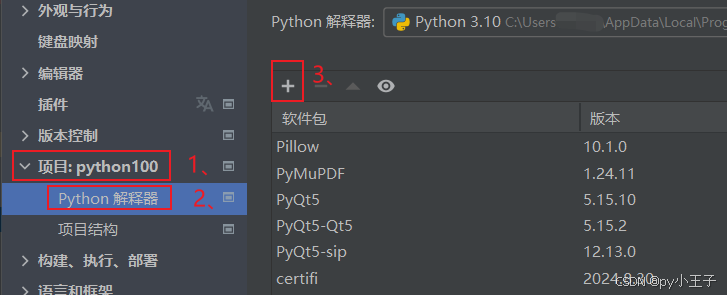
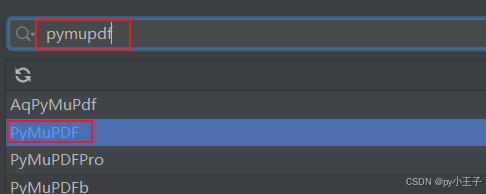
二、安装
PyMuPDF(包含fitz模块)可以通过Python的包管理器pip来安装。
在命令行工具中输入以下命令:
pip install PyMuPDF
这将从Python包索引下载并安装PyMuPDF及其依赖项。
或者

三、基本功能
1、打开PDF文件:
使用fitz.open()函数可以打开一个PDF文件,并返回一个表示该文件的对象。例如:
import fitz
doc = fitz.open("example.pdf")2、获取页面数量:
通过page_count属性可以获取PDF文件的总页数。例如:
page_count = doc.page_count
print("Number of pages:", page_count)3、提取文本:
使用get_text()方法可以提取当前页面的所有文本。例如:
text = page.get_text()
print("Extracted text:", text)此外,还可以遍历文档中的每一页,提取每一页的文本。
4、保存修改后的PDF:
使用save()方法可以保存对PDF文件所做的更改。例如:
doc.save("modified_example.pdf")其他功能:
插入新的页面:使用
fitz.new_page()创建新页面,然后使用insert_pdf()方法将新页面插入到指定位置。合并多个PDF文件:创建一个空的PDF文档对象,然后遍历要合并的PDF文件,将它们的页面插入到新的文档对象中,最后保存合并后的PDF。
提取PDF中的图片:遍历PDF的每一页,使用
get_images()方法获取页面上的所有图像,并保存它们。提取PDF中的表格:使用
find_tables()方法获取页面上的表格,然后可以将表格数据保存为CSV格式文件。 四、应用场景
四、应用场景
PyMuPDF(fitz)适用于需要处理PDF文件的各种场景,如文本提取、页面操作、PDF合并与分割等。它以其快速、高效和易于使用而著称,是处理PDF文件的理想选择。
例如:PDF文件拆分任意页数.py
import fitz
import os
def split_pdf(pdf_path):
# 检查输入的PDF文件是否存在
if not os.path.exists(pdf_path):
print("您输入的路径无pdf文件!")
return
# 打开pdf文件
doc = fitz.open(pdf_path)
page_count = len(doc)
print(f"该pdf文件页数为:{page_count}")
while True:
# 获取起始页码(0基索引)
page_num1 = None
while True:
try:
user_input = input("请输入您拆分的起始页码(输入q/Q退出):")
if user_input.lower() == 'q':
doc.close()
return
page_num1 = int(user_input) - 1
if page_num1 < 0 or page_num1 >= page_count:
print("起始页码无效,请重新输入。")
else:
break
except ValueError:
print("请输入有效的起始页码或q/Q退出。")
# 获取结束页码(0基索引)
page_num2 = None
while True:
try:
user_input = input("请输入您拆分的截止页码(输入q/Q退出):")
if user_input.lower() == 'q':
doc.close()
return
page_num2 = int(user_input) - 1
if page_num2 < 0 or page_num2 >= page_count:
print("截止页码无效,请重新输入。")
else:
break
except ValueError:
print("请输入有效的截止页码或q/Q退出。")
# 创建一个新的PDF文档并插入指定的页面范围
new_doc = fitz.open()
new_doc.insert_pdf(doc, from_page=page_num1, to_page=page_num2)
# 获取用户输入的PDF基础名字和保存目录
pdf_base_name = input("请输入您的PDF基础名字:")
if not pdf_base_name.lower().endswith('.pdf'):
pdf_name = f"{pdf_base_name}_{page_num1 + 1}-{page_num2 + 1}.pdf"
else:
pdf_name = f"{pdf_base_name[:-4]}_{page_num1 + 1}-{page_num2 + 1}.pdf"
save_dir = input("请输入您想要保存PDF的目录(例如:C:/Users/YourName/Documents/):")
# 确保目录末尾有斜杠,并检查目录是否存在
if not save_dir.endswith(os.sep) and save_dir != "":
save_dir += os.sep
os.makedirs(save_dir, exist_ok=True)
output_path = os.path.join(save_dir, pdf_name)
new_doc.save(output_path)
new_doc.close()
print(f"Saved: {output_path}")
# 检查是否继续拆分或退出
is_continue = input("是否继续拆分其他页面范围(q/Q退出)?").strip().lower()
if is_continue == 'q':
doc.close()
break
# 调用函数进行PDF拆分
pdf_path = input("请输入您需要拆分的PDF路径:")
split_pdf(pdf_path)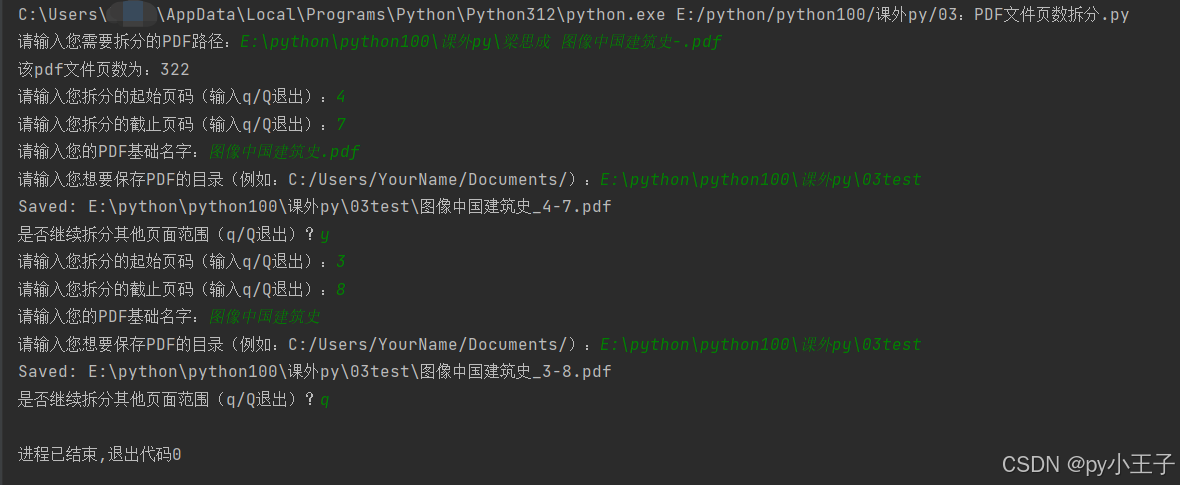
总结
通过本文的介绍,我们了解了一款基于Python编写的PDF拆分脚本。这款脚本以其简洁的界面、高效的功能和易用的操作方式,为用户提供了极大的便利。无论是处理单个PDF文件还是批量拆分多个文件,它都能轻松应对。通过简单的命令行交互,用户可以快速指定要拆分的页面范围,并生成新的PDF文档。此外,脚本还具备完善的错误处理机制,确保用户在操作过程中不会遇到困扰。总之,这款Python脚本是处理PDF文件时不可或缺的一款实用工具,它能够让你的工作更加高效、轻松。如果你经常需要处理PDF文件,那么这款脚本绝对值得一试。
本文来源于#py小王子,由@蜜芽 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/3157.html



")

















