在数据分析领域,数据汇总和统计是不可或缺的步骤。Python的pandas库提供了强大的工具来处理这些任务,其中pivot_table函数尤为突出。本文将详细介绍如何使用pandas的pivot_table函数进行数据汇总和分析,帮助读者掌握这一强大工具,提高数据处理效率。无论你是初学者还是经验丰富的数据科学家,本文都将为你提供实用的技巧和示例代码,让你轻松应对各种数据汇总需求。
什么是透视表?
经常做报表的小伙伴对数据透视表应该不陌生,在excel中利用数据透视表可以快速地进行分类汇总,自由组合字段快速计算,而这些只需要拖拉拽就可以实现。
维基百科对透视表(pivot table)解释是:
A pivot table is a table of statistics that summarizes the data of a more extensive table.
透视表是一种汇总了更广泛表数据的统计信息表。
典型的数据格式是扁平的,只包含行和列,不方便总结信息:
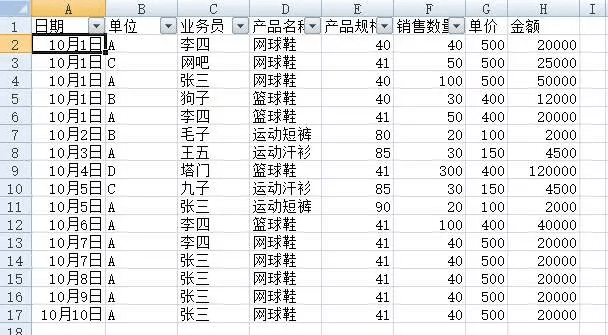
而数据透视表可以快速抽取有用的信息:
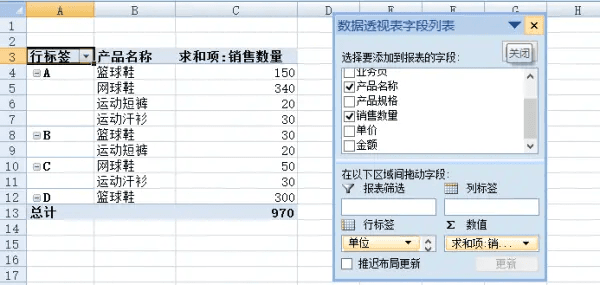
pandas也有透视表?
pandas作为编程领域最强大的数据分析工具之一,自然也有透视表的功能。
在pandas中,透视表操作由pivot_table()函数实现,不要小看只是一个函数,但却可以玩转数据表,解决大麻烦。
pivot_table使用方法:
pandas.pivot_table(*data*, *values=None*, *index=None*, *columns=None*, *aggfunc='mean'*, *fill_value=None*, *margins=False*, *dropna=True*, *margins_name='All'*, *observed=False*)
参数解释:
data:dataframe格式数据
values:需要汇总计算的列,可多选
index:行分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的行索引
columns:列分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的列索引
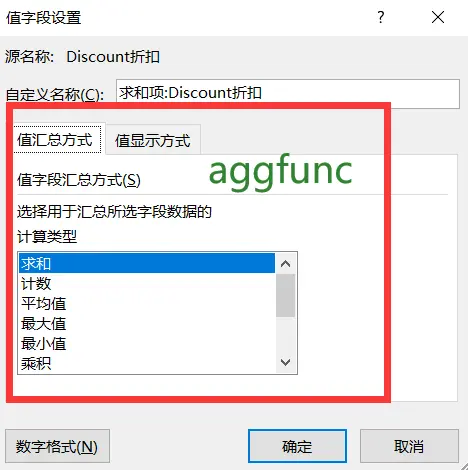
aggfunc:聚合函数或函数列表,默认为平均值
fill_value:设定缺失替换值
margins:是否添加行列的总计
dropna:默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
margins_name:汇总行列的名称,默认为All
observed:是否显示观测值
注意,在所有参数中,values、index、columns最为关键,它们分别对应excel透视表中的值、行、列:

参数aggfunc对应excel透视表中的值汇总方式,但比excel的聚合方式更丰富:
如何使用pivot_table?
下面拿数据练一练,示例数据表如下:
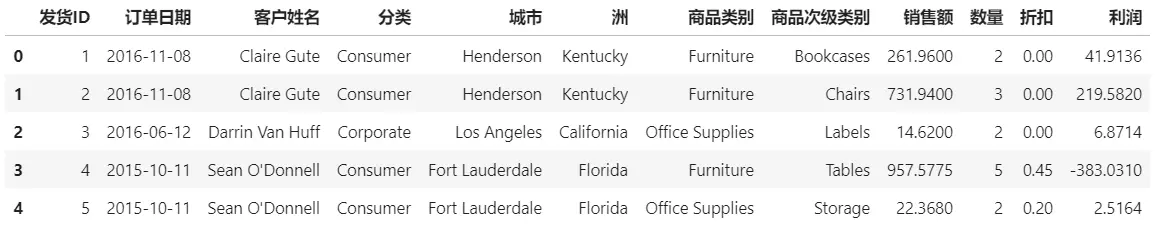
该表为用户订单数据,有订单日期、商品类别、价格、利润等维度。
首先导入数据:
data = pd.read_excel("E:\\订单数据.xlsx")
data.head()接下来使用透视表做分析:
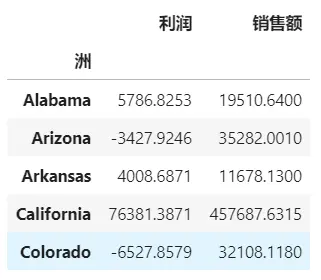
计算每个州销售总额和利润总额
result1 = pd.pivot_table(data,index='洲' , values = ['销售额','利润'] , aggfunc = np.sum) result1.head()
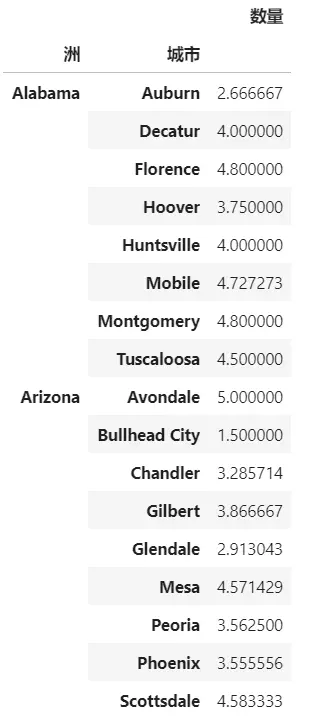
计算每个洲每个城市每单平均销售量
result2 = pd.pivot_table(data,index=['洲','城市'],aggfunc=np.mean,values=['数量']) result2.head(20)
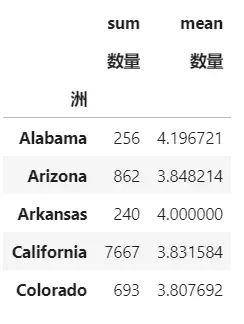
计算每个洲的总销量和每单平均销量
result3 = pd.pivot_table(data,index=['洲'],aggfunc=[np.sum,np.mean],values=['数量']) result3.head()
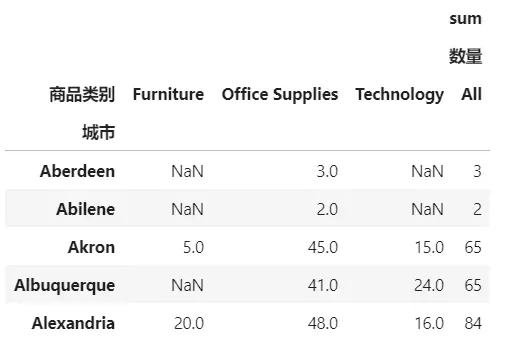
看每个城市(行)每类商品(列)的总销售量,并汇总计算
result4 = pd.pivot_table(data,index=['城市'],columns=['商品类别'],aggfunc=[np.sum],values=['数量'],margins=True) result4.head()
总结
本文介绍了pandas pivot_table函数的使用,其透视表功能基本和excel类似,但pandas的聚合方式更加灵活和多元,处理大数据也更快速,大家有兴趣可探索更高级的用法。
本文通过详细的示例代码,展示了如何使用pandas的pivot_table函数进行数据汇总和分析。从基本的销售总额和利润总额计算,到复杂的多维度数据聚合,pivot_table函数都表现出色。通过本文的学习,读者不仅能够理解透视表的基本概念,还能掌握如何在实际项目中灵活运用这一功能,提高数据处理的效率和准确性。无论是处理小规模数据集还是大规模数据集,pandas的pivot_table都是一个值得信赖的工具。希望本文的内容能为你的数据分析之旅提供有力支持。
本文来源于#Python大数据分析,由@蜜芽 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/2529.html
函数的语法及示例代码详解")
和nunique()函数区别详解")
的方法详解")















