在当今信息爆炸的时代,敏感词过滤已成为许多应用程序不可或缺的一部分,无论是社交媒体、在线论坛还是即时通讯工具,都需要对发布内容进行审核以确保信息安全和合规性。使用Java开发敏感词检测工具是一种常见且有效的解决方案。本文将详细介绍如何使用Java来实现一个简单的敏感词检测工具,包括所需的步骤和示例代码,帮助开发者快速上手并应用于实际项目中。
开发步骤
引入 Maven 依赖
引入最新的版本即可,见附录开源地址。
<dependency> <groupId>com.github.houbb</groupId> <artifactId>sensitive-word</artifactId> <version>0.18.0</version> </dependency>
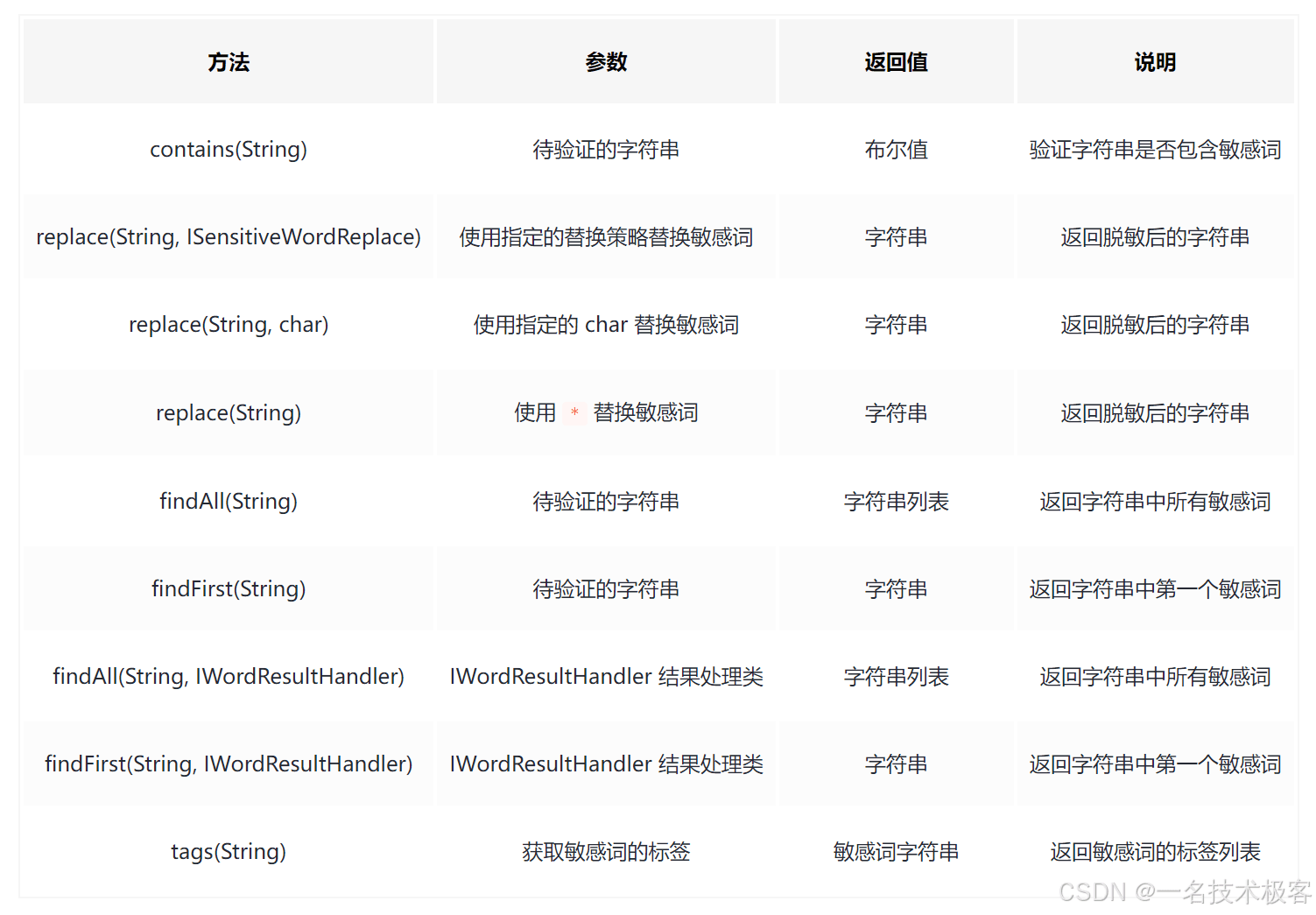
核心方法使用实例
包含了主要的一些功能和方法,如下所示:
常规用法 查找替换;
指定替换字符串;
检测忽略大小写,特殊字符,重复字符,简繁体,中英文等;
自定义替换检测策略示例;
package com.example.demo;
import com.github.houbb.sensitive.word.api.IWordContext;
import com.github.houbb.sensitive.word.api.IWordReplace;
import com.github.houbb.sensitive.word.api.IWordResult;
import com.github.houbb.sensitive.word.bs.SensitiveWordBs;
import com.github.houbb.sensitive.word.core.SensitiveWordHelper;
import com.github.houbb.sensitive.word.support.result.WordResultHandlers;
import com.github.houbb.sensitive.word.utils.InnerWordCharUtils;
import java.util.List;
public class SensitiveWordTestDemo {
public static void main(String[] args) {
//testNormal();
//testDefineReplace();
//testSensitiveWordResultHandler();
//testOtherFeatures();
testMoreFeatures();
}
// 常规使用案例:替换敏感词
public static void testNormal() {
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
System.out.println("是否包含铭感词:" + SensitiveWordHelper.contains(text));
System.out.println("查找第一个铭感词:" + SensitiveWordHelper.findFirst(text));
System.out.println("查找所有铭感词:" + SensitiveWordHelper.findAll(text));
System.out.println("替换所有铭感词:" + SensitiveWordHelper.replace(text));
System.out.println("替换所有铭感词(指定替换符号):" + SensitiveWordHelper.replace(text, '⭐'));
}
/**
* 此案例讲解:IWordResultHandler 可以对敏感词的结果进行处理,允许用户自定义。
*/
public static void testSensitiveWordResultHandler() {
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
List<String> wordList = SensitiveWordHelper.findAll(text);
//Assert.assertEquals("[五星红旗, 毛主席, 天安门]", wordList.toString());
System.out.println("1.查找到所有铭感词:" + wordList);
List<String> wordList2 = SensitiveWordHelper.findAll(text, WordResultHandlers.word());
//Assert.assertEquals("[五星红旗, 毛主席, 天安门]", wordList2.toString());
System.out.println("2.默认内置处理(同直接查找到所有敏感词):" + wordList2);
List<IWordResult> wordList3 = SensitiveWordHelper.findAll(text, WordResultHandlers.raw());
//Assert.assertEquals("[WordResult{startIndex=0, endIndex=4}, WordResult{startIndex=9, endIndex=12}, WordResult{startIndex=18, endIndex=21}]", wordList3.toString());
System.out.println("3.查找敏感词单词本身的起始位置到终止位置:" + wordList3);
}
// 实例:常规忽略检测特性
public static void testOtherFeatures() {
System.out.println("\n其他属性\n");
String text = "fuCK the bad words.";
String word = SensitiveWordHelper.findFirst(text);
//Assert.assertEquals("fuCK", word);
System.out.println("忽略大小写:" + word);
System.out.println("替换大小写字符:" + SensitiveWordHelper.replace(text));
text = "fuck the bad words.";
word = SensitiveWordHelper.findFirst(text);
//Assert.assertEquals("fuck", word);
System.out.println("忽略半圆角:" + word);
System.out.println("替换半圆角字符:" + SensitiveWordHelper.replace(text));
text = "这个是我的微信:9⓿二肆⁹₈③⑸⒋➃㈤㊄";
List<String> wordList = SensitiveWordBs.newInstance().enableNumCheck(true).init().findAll(text);
//Assert.assertEquals("[9⓿二肆⁹₈③⑸⒋➃㈤㊄]", wordList.toString());
System.out.println("忽略数字的写法:" + wordList.toString());
System.out.println("替换数字字符:" + SensitiveWordBs.newInstance().enableNumCheck(true).init().replace(text));
text = "我爱我的祖国和五星紅旗。";
List<String> wordList1 = SensitiveWordHelper.findAll(text);
//Assert.assertEquals("[五星紅旗]", wordList1.toString());
System.out.println("检测敏感词简繁体格式是否存在:" + wordList1.toString());
text = "Ⓕⓤc⒦ the bad words";
List<String> wordList2 = SensitiveWordHelper.findAll(text);
//Assert.assertEquals("[Ⓕⓤc⒦]", wordList2.toString());
System.out.println("检测敏感词是否存在英文的书写格式:" + wordList2.toString());
text = "ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦ the bad words";
List<String> wordList3 = SensitiveWordBs.newInstance()
.ignoreRepeat(true)
.init()
.findAll(text);
//Assert.assertEquals("[ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦]", wordList3.toString());
System.out.println("检测重复词每个字符是否重复:" + wordList3.toString());
}
// 实例:更多检测特性
public static void testMoreFeatures() {
// 1.邮箱检测(邮箱等个人信息,默认未启用。)
String text = "楼主好人,邮箱 sensitiveword@xx.com";
List<String> wordList = SensitiveWordBs.newInstance().enableEmailCheck(true).init().findAll(text);
//Assert.assertEquals("[sensitiveword@xx.com]", wordList.toString());
System.out.println("是否存在邮箱:" + wordList.toString());
// 2.连续数字检测(一般用于过滤手机号/QQ等广告信息,默认未启用。)
text = "你懂得:12345678";
// 默认检测 8 位
List<String> wordList1 = SensitiveWordBs.newInstance()
.enableNumCheck(true)
.init().findAll(text);
//Assert.assertEquals("[12345678]", wordList.toString());
System.out.println("是否存在连续数字字符串:" + wordList1);
// 指定数字的长度,避免误杀
List<String> wordList2 = SensitiveWordBs.newInstance()
.enableNumCheck(true)
.numCheckLen(9)
.init().findAll(text);
//Assert.assertEquals("[]", wordList2.toString());
System.out.println("是否存在连续数字字符串2:" + wordList2.toString());
// 3.网址检测(用于过滤常见的网址信息,默认未启用, v0.18.0 优化 URL 检测,更加严格,降低误判率)
text = "点击链接 https://www.baidu.com 查看答案";
SensitiveWordBs sensitiveWordBs = SensitiveWordBs.newInstance().enableUrlCheck(true).init();
List<String> wordList3 = sensitiveWordBs.findAll(text);
//Assert.assertEquals("[https://www.baidu.com]", wordList3.toString());
//Assert.assertEquals("点击链接 ********************* 查看答案", sensitiveWordBs.replace(text));
System.out.println("是否存在网址信息:" + wordList3.toString());
System.out.println("是否存在网址信息2并替换:" + sensitiveWordBs.replace(text));
// 4.IPv4 检测: 避免用户通过 ip 绕过网址检测等,默认未启用。
text = "个人网站,如果网址打不开可以访问 127.0.0.1。";
SensitiveWordBs sensitiveWordBs2 = SensitiveWordBs.newInstance().enableIpv4Check(true).init();
List<String> wordList4 = sensitiveWordBs2.findAll(text);
//Assert.assertEquals("[127.0.0.1]", wordList4.toString());
System.out.println("是否存在 IPv4:" + wordList4.toString());
}
// 实例:自定义检测替换策略
public static void testDefineReplace() {
System.out.println("自定义敏感词替换策略:(策略:指定敏感词替换)");
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
MySensitiveWordReplace replace = new MySensitiveWordReplace();
String result = SensitiveWordHelper.replace(text, replace);
System.out.println("自定义替换策略结果:" + result);
}
}
class MySensitiveWordReplace implements IWordReplace {
@Override
public void replace(StringBuilder stringBuilder, char[] chars, IWordResult wordResult, IWordContext iWordContext) {
String sensitiveWord = InnerWordCharUtils.getString(chars, wordResult);
// 自定义不同的敏感词替换策略,可以从数据库等地方读取
if ("五星红旗".equals(sensitiveWord)) {
stringBuilder.append("国家旗帜");
} else if ("毛主席".equals(sensitiveWord)) {
stringBuilder.append("教员");
} else {
// 其他默认使用 * 代替
int wordLength = wordResult.endIndex() - wordResult.startIndex();
for (int i = 0; i < wordLength; i++) {
stringBuilder.append('*');
}
}
}
}输出结果展示:
是否包含铭感词:true
查找第一个铭感词:五星红旗
查找所有铭感词:[五星红旗, 毛主席, 天安门]
替换所有铭感词:****迎风飘扬,***的画像屹立在***前。
替换所有铭感词(指定替换符号):⭐⭐⭐⭐迎风飘扬,⭐⭐⭐的画像屹立在⭐⭐⭐前。
自定义敏感词替换策略:(策略:指定敏感词替换)
自定义替换策略结果:国家旗帜迎风飘扬,教员的画像屹立在***前。
1.查找到所有铭感词:[五星红旗, 毛主席, 天安门]
2.默认内置处理(同直接查找到所有敏感词):[五星红旗, 毛主席, 天安门]
3.查找敏感词单词本身的起始位置到终止位置:[WordResult{startIndex=0, endIndex=4, type='WORD'}, WordResult{startIndex=9, endIndex=12, type='WORD'}, WordResult{startIndex=18, endIndex=21, type='WORD'}]其他属性
忽略大小写:fuCK
替换大小写字符:**** the bad words.
忽略半圆角:fuck
替换半圆角字符:**** the bad words.
忽略数字的写法:[9⓿二肆⁹₈③⑸⒋➃㈤㊄]
替换数字字符:这个是我的微信:************
检测敏感词简繁体格式是否存在:[五星紅旗]
检测敏感词是否存在英文的书写格式:[Ⓕⓤc⒦]
检测重复词每个字符是否重复:[ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦]
是否存在邮箱:[sensitiveword@xx.com]
是否存在连续数字字符串:[12345678]
是否存在连续数字字符串2:[]
是否存在网址信息:[https://www.baidu.com]
是否存在网址信息2并替换:点击链接 ********************* 查看答案
是否存在 IPv4:[127.0.0.1]
核心方法:查找 / 替换
更多的检测策略(自定义)
邮箱-网址-IPV4-连续字符检测
// 实例:更多检测特性
public static void testMoreFeatures() {
// 1.邮箱检测(邮箱等个人信息,默认未启用。)
String text = "楼主好人,邮箱 sensitiveword@xx.com";
List<String> wordList = SensitiveWordBs.newInstance().enableEmailCheck(true).init().findAll(text);
//Assert.assertEquals("[sensitiveword@xx.com]", wordList.toString());
System.out.println("是否存在邮箱:" + wordList.toString());
// 2.连续数字检测(一般用于过滤手机号/QQ等广告信息,默认未启用。)
text = "你懂得:12345678";
// 默认检测 8 位
List<String> wordList1 = SensitiveWordBs.newInstance()
.enableNumCheck(true)
.init().findAll(text);
//Assert.assertEquals("[12345678]", wordList.toString());
System.out.println("是否存在连续数字字符串:" + wordList1);
// 指定数字的长度,避免误杀
List<String> wordList2 = SensitiveWordBs.newInstance()
.enableNumCheck(true)
.numCheckLen(9)
.init().findAll(text);
//Assert.assertEquals("[]", wordList2.toString());
System.out.println("是否存在连续数字字符串2:" + wordList2.toString());
// 3.网址检测(用于过滤常见的网址信息,默认未启用, v0.18.0 优化 URL 检测,更加严格,降低误判率)
text = "点击链接 https://www.baidu.com 查看答案";
SensitiveWordBs sensitiveWordBs = SensitiveWordBs.newInstance().enableUrlCheck(true).init();
List<String> wordList3 = sensitiveWordBs.findAll(text);
//Assert.assertEquals("[https://www.baidu.com]", wordList3.toString());
//Assert.assertEquals("点击链接 ********************* 查看答案", sensitiveWordBs.replace(text));
System.out.println("是否存在网址信息:" + wordList3.toString());
System.out.println("是否存在网址信息2并替换:" + sensitiveWordBs.replace(text));
// 4.IPv4 检测: 避免用户通过 ip 绕过网址检测等,默认未启用。
text = "个人网站,如果网址打不开可以访问 127.0.0.1。";
SensitiveWordBs sensitiveWordBs2 = SensitiveWordBs.newInstance().enableIpv4Check(true).init();
List<String> wordList4 = sensitiveWordBs2.findAll(text);
//Assert.assertEquals("[127.0.0.1]", wordList4.toString());
System.out.println("是否存在 IPv4:" + wordList4.toString());
}常规检测:大小写-特殊字符-重复字符-简繁体等
// 实例:常规忽略检测特性
public static void testOtherFeatures() {
System.out.println("\n其他属性\n");
String text = "fuCK the bad words.";
String word = SensitiveWordHelper.findFirst(text);
//Assert.assertEquals("fuCK", word);
System.out.println("忽略大小写:" + word);
System.out.println("替换大小写字符:" + SensitiveWordHelper.replace(text));
text = "fuck the bad words.";
word = SensitiveWordHelper.findFirst(text);
//Assert.assertEquals("fuck", word);
System.out.println("忽略半圆角:" + word);
System.out.println("替换半圆角字符:" + SensitiveWordHelper.replace(text));
text = "这个是我的微信:9⓿二肆⁹₈③⑸⒋➃㈤㊄";
List<String> wordList = SensitiveWordBs.newInstance().enableNumCheck(true).init().findAll(text);
//Assert.assertEquals("[9⓿二肆⁹₈③⑸⒋➃㈤㊄]", wordList.toString());
System.out.println("忽略数字的写法:" + wordList.toString());
System.out.println("替换数字字符:" + SensitiveWordBs.newInstance().enableNumCheck(true).init().replace(text));
text = "我爱我的祖国和五星紅旗。";
List<String> wordList1 = SensitiveWordHelper.findAll(text);
//Assert.assertEquals("[五星紅旗]", wordList1.toString());
System.out.println("检测敏感词简繁体格式是否存在:" + wordList1.toString());
text = "Ⓕⓤc⒦ the bad words";
List<String> wordList2 = SensitiveWordHelper.findAll(text);
//Assert.assertEquals("[Ⓕⓤc⒦]", wordList2.toString());
System.out.println("检测敏感词是否存在英文的书写格式:" + wordList2.toString());
text = "ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦ the bad words";
List<String> wordList3 = SensitiveWordBs.newInstance()
.ignoreRepeat(true)
.init()
.findAll(text);
//Assert.assertEquals("[ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦]", wordList3.toString());
System.out.println("检测重复词每个字符是否重复:" + wordList3.toString());
}自定义检测替换策略
自定义检测替换
class MySensitiveWordReplace implements IWordReplace {
@Override
public void replace(StringBuilder stringBuilder, char[] chars, IWordResult wordResult, IWordContext iWordContext) {
String sensitiveWord = InnerWordCharUtils.getString(chars, wordResult);
// 自定义不同的敏感词替换策略,可以从数据库等地方读取
if ("五星红旗".equals(sensitiveWord)) {
stringBuilder.append("国家旗帜");
} else if ("毛主席".equals(sensitiveWord)) {
stringBuilder.append("教员");
} else {
// 其他默认使用 * 代替
int wordLength = wordResult.endIndex() - wordResult.startIndex();
for (int i = 0; i < wordLength; i++) {
stringBuilder.append('*');
}
}
}
}使用实例:
// 实例:自定义检测替换策略
public static void testDefineReplace() {
System.out.println("自定义敏感词替换策略:(策略:指定敏感词替换)");
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
MySensitiveWordReplace replace = new MySensitiveWordReplace();
String result = SensitiveWordHelper.replace(text, replace);
System.out.println("自定义替换策略结果:" + result);
}开源地址
https://github.com/houbb/sensitive-word
总结
通过本文的介绍,您已经了解了使用Java开发敏感词检测工具的基本步骤,包括创建敏感词库、实现检测算法以及测试工具的有效性。提供的示例代码展示了如何在实际项目中应用这些知识。敏感词检测工具不仅可以帮助企业维护信息发布的规范性,还能有效防止不良信息的传播。希望本文的内容对您有所帮助,期待您在实际开发中取得更多成果。
本文来源于#一名技术极客,由@蜜芽 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/2194.html





















