在数据库管理中,数据的准确性与完整性至关重要。然而,在实际应用中,由于各种原因,如数据导入错误、系统故障或人为操作失误,常常会导致数据库中出现重复记录。这不仅浪费存储空间,还可能影响数据查询的效率和准确性。MySQL作为一款广泛使用的开源数据库管理系统,提供了多种有效的数据去重方法。本文将深入解析MySQL中数据去重的三种方法,帮助数据库管理员和开发人员更好地维护数据的唯一性。
一、背景
最近在和系统模块做数据联调,其中有一个需求是将两个角色下的相关数据对比后将最新的数据返回出去,于是就想到了去重,再次做一个总结。
二、数据去重三种方法使用
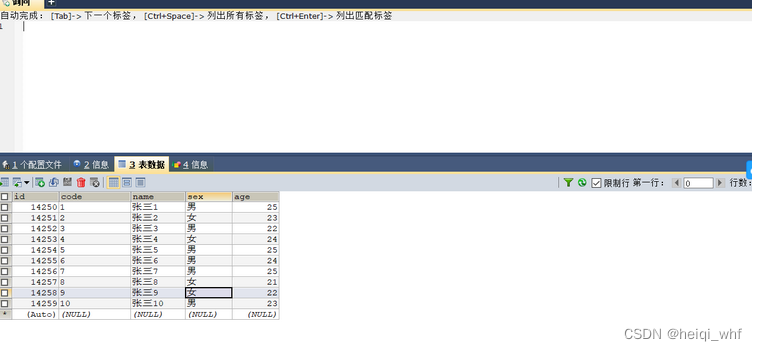
1.通过MySQL DISTINCT:去重(过滤重复数据)
1.1.在使用 mysql SELECT 语句查询数据的时候返回的是所有匹配的行。
SELECT t.age FROM t_user t
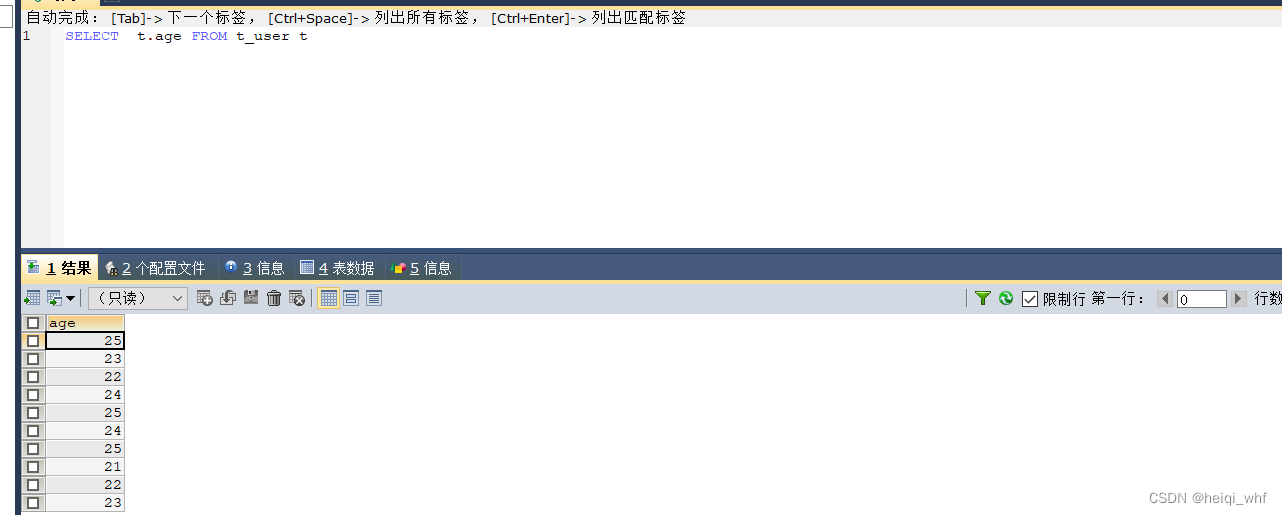
可以看到查询结果返回了 10 条记录,其中有一些重复的 age 值,有时出于对数据分析的要求,需要消除重复的记录值。
1.2.DISTINCT 关键字指示 MySQL 消除重复的记录值。
语法格式为:
SELECT DISTINCT <字段名> FROM <表名>;
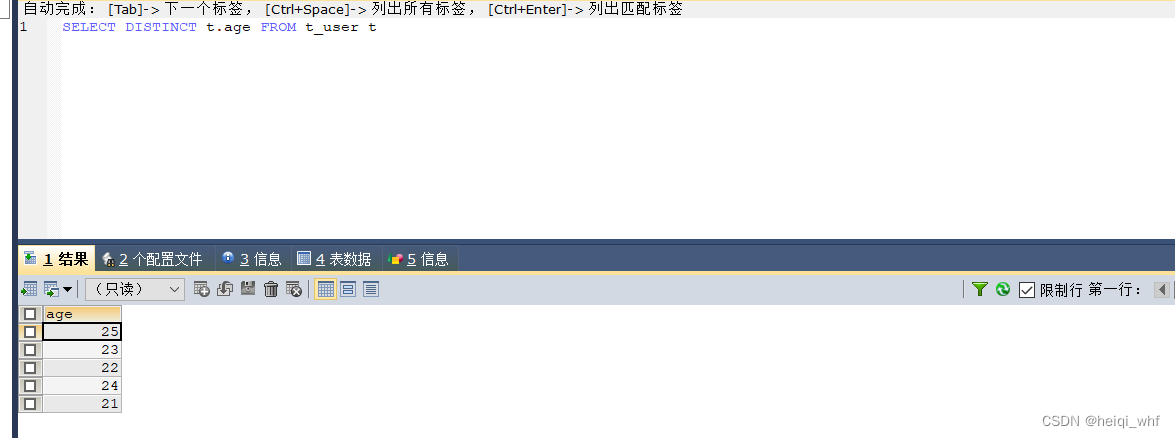
SELECT DISTINCT t.age FROM t_user t
由运行结果可以看到,这次查询结果只返回了 5 条记录的 age 值,且没有重复的值。
ps:
其中,“字段名”为需要消除重复记录的字段名称,多个字段时用逗号隔开。
使用 DISTINCT 关键字时需要注意以下几点:
DISTINCT 关键字只能在 SELECT 语句中使用。
在对一个或多个字段去重时,DISTINCT 关键字必须在所有字段的最前面。
如果 DISTINCT 关键字后有多个字段,则会对多个字段进行组合去重,也就是说,只有多个字段组合起来完全是一样的情况下才会被去重。
2.group by
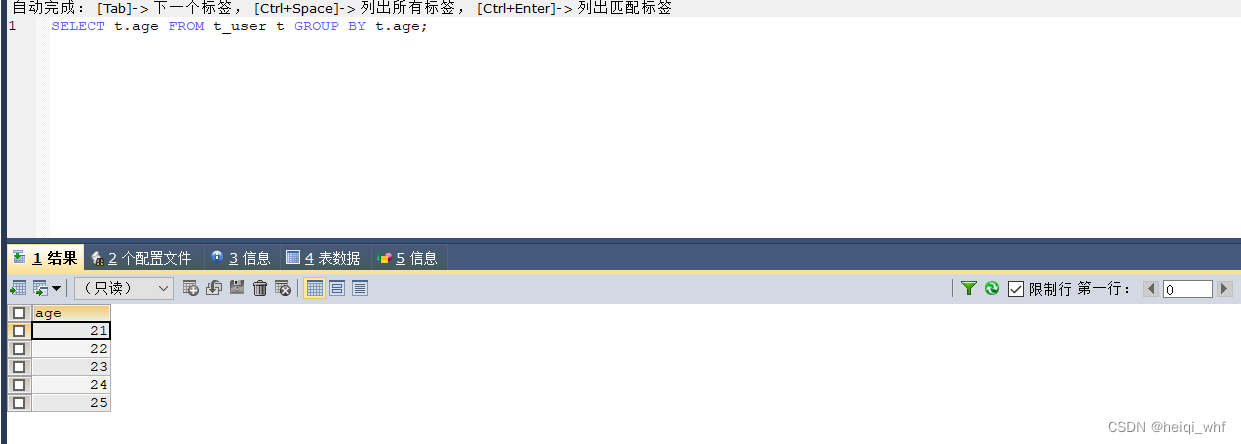
SELECT t.age FROM t_user t GROUP BY t.age;
3.row_number窗口函数
语法格式为:
row_number() over (partition by <用于分组的字段名> order by <用于组内排序的字段名>)
项目使用的去重:
select * from (select t.*,row_number() over(partition by t.children_id order by t.update_time DESC) rn from mdm_data_authority_view_info t where t.DATA_CLASS_ID = '分类id' AND t.DATA_ROLE_ID IN ( '角色id', '角色id' )) where rn = 1;
三、总结
数据去重是数据库管理中的一个重要任务,确保数据的准确性和高效性。本文详细介绍了MySQL中数据去重的三种方法:使用DISTINCT关键字、group by以及通过SQL窗口函数。每种方法都有其适用场景和优缺点,用户可以根据实际需求选择最合适的方式。通过掌握这些数据去重技巧,数据库管理员和开发人员可以更加高效地管理数据,提升系统的整体性能。在未来的工作中,我们将继续探索更多优化数据管理的方法,为用户提供更高质量的数据服务。
本文来源于#heiqi_whf,由@ZhanShen 整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/1694.html
函数实现字符串拼接的方法详解")

函数的使用方法及示例详解")


















