在当今数据驱动的世界中,获取和利用网络上的信息变得尤为重要。无论是为了市场分析、竞争情报还是内容聚合,网页抓取都是一项关键任务。然而,传统的网页抓取方法往往复杂且容易受到网站结构变化的影响。正因如此,一款名为Firecrawl的开源爬虫类框架应运而生,它承诺能够将任意网站转换为API接口,从而简化数据获取的过程。本文ZHANID将深入探讨Firecrawl的功能、使用方法及其在实际应用中的潜力。
Firecrawl是什么
Firecrawl 是一款功能强大的 开源爬虫类框架,旨在帮助开发者轻松抓取和转换网页数据为API 接口。它可以获取任意 URL,对其进行抓取,并将其转换为干净的 Markdown 或结构化数据。无论您是需要抓取单个页面还是整个网站,Firecrawl 都能提供高效且便捷的解决方案。Firecrawl的核心优势在于其简单易用的API接口,以及强大的数据清洗和格式化功能。
项目开源地址:https://github.com/mendableai/firecrawl
Firecrawl的核心功能
URL抓取:Firecrawl可以从给定的URL抓取网页内容。
子页面抓取:它可以自动发现并抓取所有可访问的子页面。
数据格式化:支持将抓取的数据转换为干净的Markdown或结构化数据。
API接口:提供易于使用的API,方便开发者集成到自己的项目中。
无站点地图要求:不需要依赖站点地图,只需提供起始URL即可。
Firecrawl的优势
简化数据获取:通过API接口,开发者可以轻松获取网站内容,无需编写复杂的爬虫代码。
高效的数据处理:内置的数据清洗和格式化功能,使得获取的数据更加整洁和结构化。
灵活的使用方式:支持通过API密钥进行访问,提供免费和付费计划,满足不同用户的需求。
Firecrawl使用方法
要使用Firecrawl,首先需要获取API密钥。密钥分为收费和免费两种,对于非商业项目,免费计划已经足够使用。以下是如何使用Firecrawl的详细步骤:
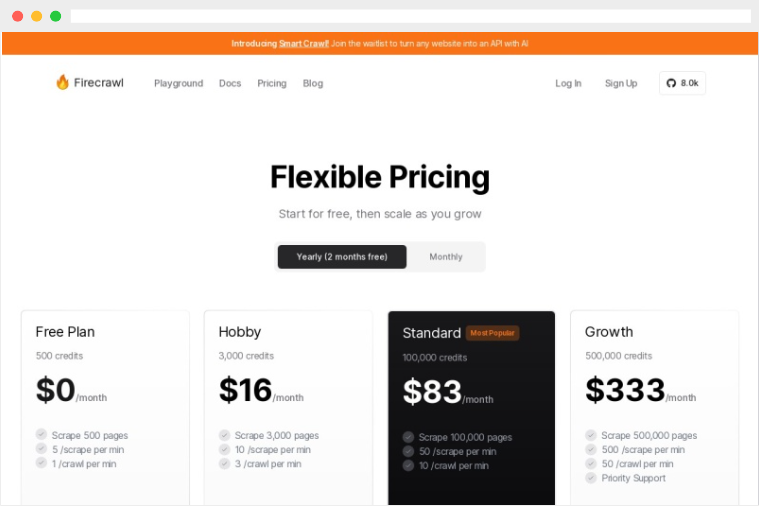
获取API密钥
访问Firecrawl官网:https://www.firecrawl.dev/pricing
注册账户并获取API密钥。
安装和配置
1、安装依赖包:使用npm安装Firecrawl的Node.js包。
npm install @mendable/firecrawl-js
2、设置API密钥:将API密钥设置为环境变量FIRECRAWL_API_KEY,或者将其作为参数传递给FirecrawlApp类。
使用Firecrawl API
抓取单个URL
可以使用scrapeUrl方法来抓取单个URL的内容。
const { FirecrawlApp } = require('@mendable/firecrawl-js');
const firecrawl = new FirecrawlApp('YOUR_API_KEY');
const url = 'https://example.com';
firecrawl.scrapeUrl(url)
.then(data => {
console.log(data);
})
.catch(error => {
console.error(error);
});爬取网站信息
使用crawlUrl方法可以爬取整个网站的信息。该方法接受起始URL和可选参数,用于指定抓取选项。
const { FirecrawlApp } = require('@mendable/firecrawl-js');
const firecrawl = new FirecrawlApp('YOUR_API_KEY');
const url = 'https://example.com';
const params = {
maxPages: 10, // 最大抓取页面数
allowedDomains: ['example.com'], // 允许的域名
outputFormat: 'markdown' // 输出格式为Markdown
};
firecrawl.crawlUrl(url, params)
.then(data => {
console.log(data);
})
.catch(error => {
console.error(error);
});检查爬取状态
可以使用checkCrawlStatus方法来检查爬取任务的状态。
const { FirecrawlApp } = require('@mendable/firecrawl-js');
const firecrawl = new FirecrawlApp('YOUR_API_KEY');
const crawlId = 'YOUR_CRAWL_ID';
firecrawl.checkCrawlStatus(crawlId)
.then(status => {
console.log(status);
})
.catch(error => {
console.error(error);
});使用LLM格式化数据
Firecrawl还支持使用LLM(Large Language Models)自动格式化抓取的数据。
const { FirecrawlApp } = require('@mendable/firecrawl-js');
const firecrawl = new FirecrawlApp('YOUR_API_KEY');
const url = 'https://example.com';
firecrawl.crawlUrl(url)
.then(data => {
const formattedData = firecrawl.formatDataWithLLM(data);
console.log(formattedData);
})
.catch(error => {
console.error(error);
});在搜索引擎中搜索
Firecrawl还提供了一个search方法,可以在搜索引擎中搜索查询并获取排名靠前的结果及其页面内容。
const { FirecrawlApp } = require('@mendable/firecrawl-js');
const firecrawl = new FirecrawlApp('YOUR_API_KEY');
const query = 'Web development tutorials';
firecrawl.search(query)
.then(results => {
console.log(results);
})
.catch(error => {
console.error(error);
});总结
Firecrawl作为一种API服务,提供了强大的网页抓取和数据格式化功能。通过简单的API接口,开发者可以轻松地将任意网站转换为API接口,获取干净的Markdown或结构化数据。无论是用于市场分析、竞争情报还是内容聚合,Firecrawl都能极大地简化数据获取的过程。随着更多开发者和企业的关注,Firecrawl有望成为网页抓取领域的一个重要工具。
本文由@zhanid 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/1443.html

开源的超长文本生成模型")



















